



















咨询服务热线:400-0698-860
邮箱:info@chaoqing-i.com
业务中心 - 上海超擎数智科技有限公司:上海市徐汇区龙启路158号1幢灿星大厦19层1911
业务中心 - 北京超擎数智科技有限公司:北京市海淀区北三环西路99号西海国际中心1号楼907
研发中心 - 武汉超擎数智科技有限公司:武汉东湖高新区金融港二路9号联发科武汉研发中心2楼






随着 AI 重新定义计算格局,网络已成为构建未来数据中心发展的关键支柱。大语言模型的训练性能不仅取决于计算资源,更受到底层网络敏捷性、容量和智能程度的影响。行业正从传统以 CPU 为中心的基础架构,迈向紧耦合的、GPU 驱动和网络定义的 AI 工厂。
NVIDIA 构建了一套全面的网络解决方案,以满足现代大规模 AI 训练和推理对急速流量突发、高带宽及低延迟的需求。该方案涵盖 Spectrum-X 以太网、NVIDIA Quantum InfiniBand 和 BlueField 平台。通过将计算与通信一起进行编排,NVIDIA 的网络产品组合为构建可扩展、高效且高可靠的 AI 数据中心奠定了基础,成为了推动 AI 创新的中枢神经系统。
在这篇博客中,我们将探讨 NVIDIA 的网络创新如何通过 CPO 技术,为大型 AI 工厂带来显著的能效提升和更强的可靠性。
AI 工厂基础设施与传统企业数据中心有何不同?
在传统企业数据中心中,Tier 1 交换机通常部署在每个服务器机架内,通过铜缆直接连接服务器,从而降低功耗并简化连接。这种架构能够有效满足以 CPU 为中心的、网络需求适中的工作负载。
相比之下,NVIDIA 开创的现代 AI 工厂配备了超高密的计算机架和数以千计的 GPU,能面向单一任务实现协同工作。这就需要在整个数据中心内实现最高带宽和最低的延迟,一种新的网络拓扑结构应运而生——即将 Tier 1 交换机部署在独立的机柜。这种布局显著增加了服务器与交换机之间的距离,使得光纤网络变得至关重要。由此带来的结果是功耗和光学组件数量大幅上升,如今在网卡到交换机以及交换机到交换机的连接中,均需依赖光学组件来实现高效传输。
如图 1 所示,这一演变体现了为满足大规模 AI 工作负载对高带宽和低延迟的需求,在网络拓扑和技术层面所发生的重大变革,并从根本上重塑了数据中心的物理结构与能耗特征。

图 1:横向扩展能力与 AI 密度取决于光纤连接
如何优化 AI 工厂的网络可靠性与功耗?
采用可插拔光模块的传统网络交换机依赖于多个电接口。在这些架构中,数据信号需经过一条较长的电传输路径:从交换机 ASIC 出发,经 PCB、连接器,最终到达外部光收发器,之后才能转换为光信号。如图 2 所示,这种分段式传输在每秒 200Gb/s 的通道中可能带来高达 22 dB 的电损耗。这显著增加了对复杂数字信号处理以及多个有源组件的需求。
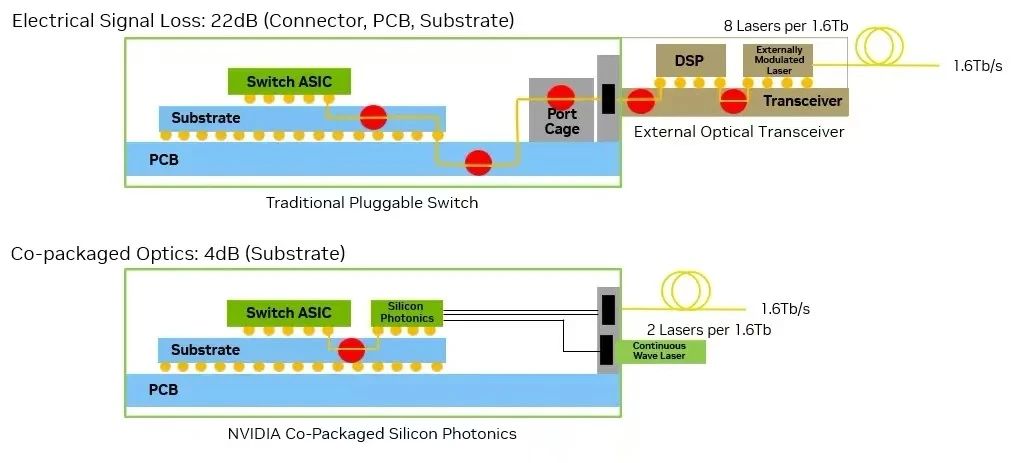
图 2:Spectrum-X Photonics 可将信号完整性提升 64 倍
采用可插拔光模块的结果就是功耗更高(每个接口通常为 30W)、发热量增加以及潜在故障点显著增多。大量的独立模块和连接不仅推高了系统功耗和组件数量,还直接影响了链路的可靠性,随着 AI 部署规模的不断扩大,这些问题将带来持续的运营挑战。各组件的典型功耗如图 3 所示。
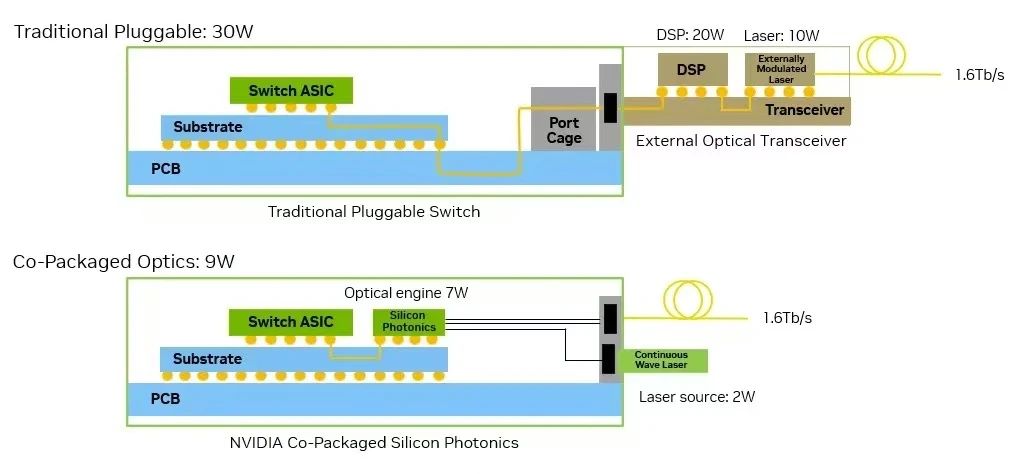
图 3:Spectrum-X Photonics 将功耗降低至 1/3.5
相比之下,采用 CPO 技术的交换机将电光转换部分直接集成到交换机封装中。光纤直接连接至和 ASIC 封装在一起的光引擎,使电信号损耗降低至约 4 dB,全通道功耗降至 9W。通过简化信号路径并消除不需要的接口,该设计显著提升了信号完整性、可靠性和能效,正是高密度、高性能 AI 数据中心所需的关键技术。
CPO 封装为 AI 工厂带来了哪些优势?
NVIDIA 推出基于 CPO 技术的系统,正是为了应对 AI 工厂前所未有的需求。通过将光引擎直接集成至交换机 ASIC,全新的 NVIDIA Quantum-X Photonics 和 Spectrum-X Photonics(如图 4 所示)将取代传统的可插拔光模块。这一创新简化了信号传输路径,显著提升了性能、能效和系统可靠性。新产品不仅在带宽和端口密度方面创下新高,更从根本上重塑了 AI 数据中心的经济模型与物理架构。

图 4:集成共封装的硅光引擎的 NVIDIA Photonics 交换 ASIC
Quantum-X Photonics 如何引领下一代 InfiniBand 网络的诞生
随着 NVIDIA 推出 Quantum-X InfiniBand Photonics 平台,NVIDIA 将 InfiniBand 交换技术提升至全新高度。该平台具备以下功能:
NVIDIA Quantum-X 采用集成硅光技术,提供无与伦比的带宽、超低延迟和卓越的运营可靠性。该 CPO 设计不仅降低了功耗、提升了可靠性,还能实现快速部署,充分满足大规模代理式 AI 工作负载对互连的严苛需求。
Spectrum-X Photonics 如何助力构建大规模以太网 AI 工厂
NVIDIA Spectrum-X Photonics 交换机将 CPO 技术革命拓展至以太网领域,专为生成式 AI 以及大规模大语言模型(LLM)的训练与推理任务而设计。全新的 Spectrum-X Photonics 产品包含两款基于液冷机箱和 Spectrum-6 ASIC 的系统:
这两个平台均基于 NVIDIA 硅光技术,大幅减少了离散组件和电接口的数量。与前代架构相比,新架构能效提升达 3.5 倍,同时通过减少整体易损光学元件数量,将系统可靠性提高了 10 倍。技术人员可享受更高的可维护性,而 AI 运营商则能将部署时间缩短至 1/ 1.3 (约 77%),并显著缩短第一个 Token 的生成时间。
NVIDIA 的 CPO 技术组得益于强大的合作伙伴生态系统的支持。这种跨行业协作不仅保障了技术性能,更确保了全球大规模 AI 基础设施部署所需的大规模量产能力与可靠性。
CPO 如何实现性能、功耗与可靠性的突破
CPO 的优势显而易见:
这些交换机系统具备业界领先的带宽性能(高达 409.6 Tb/s,512 个端口,单端口速率达 800 Gb/s),并配备高效的液冷系统,能够应对高密度、高功耗的运行环境。图 5(下图)展示了 NVIDIA Quantum-X Photonics Q3450 和 Spectrum-X Photonics 的两种型号:单 ASIC 的 SN6810,以及集成光纤重组功能的四 ASIC 型号 SN6800。
这些产品共同推动了网络架构的转型,有效满足了 AI 工作负载对高带宽和超低延迟的严苛需求。通过与先进的光学组件与强大的系统集成伙伴相结合,构建出一个面向当前及未来扩展需求高度优化的网络架构。随着超大规模数据中心对快速部署和高可靠性的要求不断提升,CPO 正从一项创新技术逐步转变为不可或缺的基础设施。

图 5:NVIDIA Quantum-X 与 Spectrum-X Photonics 交换机系统
如何开启代理式人工智能的新时代
NVIDIA Quantum-X 和 Spectrum-X Photonics 交换机标志着网络架构向专为满足大规模 AI 严苛需求而设计的全新转变。通过消除传统的电和可插拔架构带来的瓶颈,CPO 系统能够提供现代 AI 工厂所需的高性能、高能效与高可靠性。NVIDIA Quantum-X InfiniBand 交换机预计于 2026 年初上市,Spectrum-X 以太网交换机则将于 2026 年下半年推出。NVIDIA 正以此引领网络革新,为代理式 AI 时代树立优化网络的新标准。
敬请期待本博客的第二部分,我们将深入探讨 NVIDIA Quantum-X Photonics 和 Spectrum-X Photonics 平台的核心——硅光引擎的架构与工作原理,揭示推动下一代光连接成为现实的关键创新与工程突破。从芯片集成的最新进展到新型调制技术,下一篇文章将全面解析这些光电引擎在 AI 网络领域中脱颖而出的技术优势。
如需了解更多关于 NVIDIA Photonics 的信息,请访问此页面。
https://www.nvidia.cn/networking/products/silicon-photonics/

公众号


电话

需求反馈
