



















咨询服务热线:400-0698-860
邮箱:info@chaoqing-i.com
业务中心 - 上海超擎数智科技有限公司:上海市徐汇区龙启路158号1幢灿星大厦19层1911
业务中心 - 北京超擎数智科技有限公司:北京市海淀区北三环西路99号西海国际中心1号楼907
研发中心 - 武汉超擎数智科技有限公司:武汉东湖高新区金融港二路9号联发科武汉研发中心2楼





当大模型参数突破万亿、AI集群规模迈向10万卡级,算力基础设施正面临一场“架构风暴”——Scale-Up(纵向扩展)与Scale-Out(横向扩展)作为支撑 AI 算力的两大核心网络范式,正沿着截然不同的技术轨道狂飙,“低时延vs 高扩展”“高可靠vs 低成本”的极致权衡,都影响着光模块技术的迭代(LPO/NPO/CPO)。
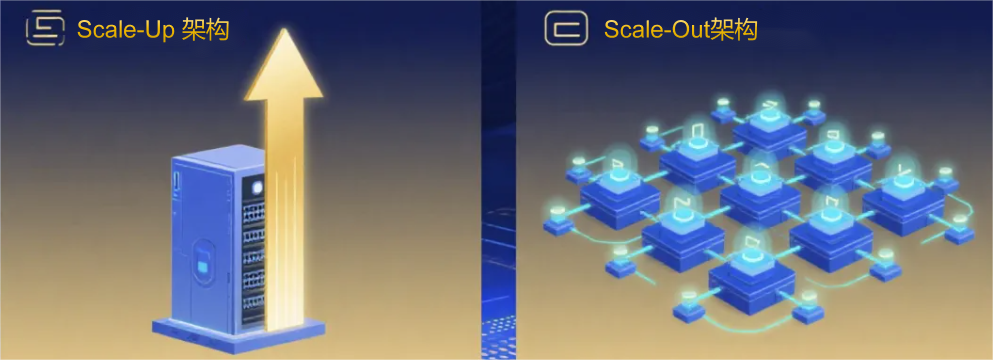
一、各有千秋:Scale-Up 与 Scale-Out 的 “核心诉求”
在AI 算力集群的架构设计中,Scale-Up 与 Scale-Out 从诞生之初就带着截然不同的“基因使命”:
Scale-Up:为“原生计算延伸”而生,死磕“低时延+ 高可靠 + 高吞吐”
Scale-Up 的本质是“GPU 原生算力的无缝扩展”—— 通过构建紧密耦合的“超节点”,将多GPU 的本地内存虚拟化为统一逻辑内存池,让 GPU 核心访问远程内存像操作本地 HBM 一样丝滑(即“内存语义”)。其追求的不是规模,而是“计算与数据的零距离”,亚微秒级时延。
Scale-Out:为“海量节点协同”而生,主打“高扩展+ 低成本 + 生态兼容”
与Scale-Up 的“紧凑高效”不同,Scale-Out 是“分布式算力的规模化聚合”—— 通过三层 / 二层 CLOS 架构,将数万甚至十万 GPU 接入统一集群,支撑 DP/PP 等并行训练场景,核心诉求是“规模优先、成本可控”。
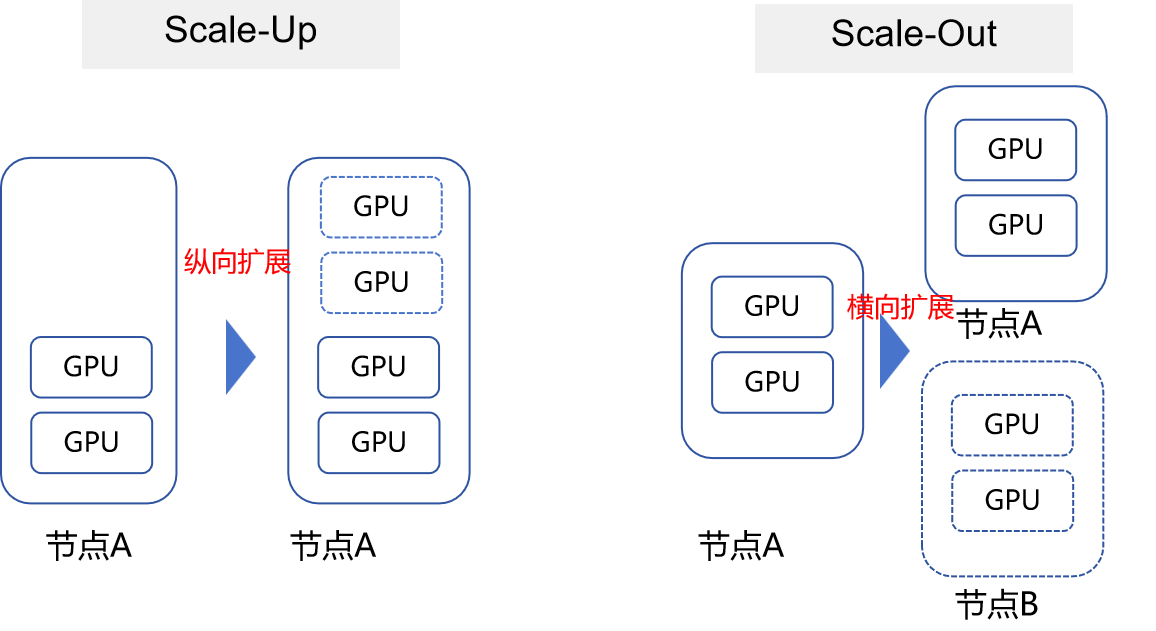
简言之,Scale-Up 是“把小集群做精”,Scale-Out 是“把大集群做通”—— 前者是 AI 算力的“精锐部队”,后者是“百万雄师”,二者共同构成了大模型训练与推理的算力底座。
二、现状深析:Scale-Up 的“超节点革命”与Scale-Out 的“扁平浪潮”
近几年,Scale-Up 与 Scale-Out 各自进入“技术爆发期”,头部厂商的实践已勾勒出清晰的演进路径:
Scale-Up:从“框式垄断”到“盒式突围”,224G 光互连成刚需
过去,Scale-Up 长期被“框式超节点”垄断,但 2025 年后“盒式超节点”的崛起打破了这一格局,形成“双架构并存”的态势:
框式超节点:高可靠的“算力堡垒”,通过“Cable 背板 + L1/L2 交换机”构建高可靠互连域。框内电互连,大带宽域;框间光纤互连,可以收敛。
盒式超节点:低成本的“效率黑马”,直接多卡GPU 封装为独立盒子,通过一级 CLOS 交换直接互连,将交换层次从 3 级精简为 1 级,互连成本占比大大降低。但其短板也极为明显:GPU 需直出光模块,第一跳可靠性依赖 XPU 的 IO-Die 处理(光模块失效和闪断带来的可靠性比电缆差100 倍)。
关于光模块和电缆可靠性对比,可参考下图OCP的数据分析:

无论架构如何演变,224G 光互连已成为 Scale-Up 的“标配”,根据咨询机构对光模块的成本预测数据,在未来3-5年,1.6T光模块售价是800G光模块的1.2~1.4倍,无论是LPO模块,还是带DSP的模块。这说明1.6T光模块优势非常明显。再加上112G的光纤也要多消耗一倍。各方面来看,224G将在未来更有优势。
Scale-Out:三层变二层、多平面组网
Scale-Out 的关键词是“精简”—— 通过架构扁平化解构传统瓶颈:三层 CLOS 谢幕,二层 10 万卡成主流。随着交换芯片的更迭,让Radix=512 成为现实,二层 CLOS 组网可直接支撑 13 万卡,无需 Core 层交换机。
DeepSeek 多平面组网:打破带宽瓶颈。DeepSeek 在 ISCA 论文中提出的“Mutli-plane 架构”,让AI-NIC 通过 4 个 200G 端口接入 4 个 CLOS 平面,每条流的数据包通过 Round-Robin 均匀分发至不同平面,接收端采用 DDP 乱序写入技术重组数据,使单 GPU Scale-Out 带宽利用率提升至 95% 以上。
三、CPO技术:重构AI网络光互连的核心力量
在Scale-Up与Scale-Out对光模块性能、能效要求持续提升的背景下,CPO(共封装光学)技术凭借“极致能效+超高带宽”,成为下一代光互连的核心方向。
CPO技术的核心突破:重构信号路径
CPO通过将光引擎与交换机ASIC共封装,简化信号传输路径(从交换机ASIC到光引擎的距离缩短至毫米级),带来革命性提升:
传统可插拔光模块单接口功耗约30W(DSP 20W+激光10W),而CPO模块总功耗仅9W(光引擎7W+激光源2W),功耗降低67%,整体能效提升3.5倍。
通过减少有源器件和去除了易发生故障的光模块,显著提高了系统正常运行时间和运行可靠性。
英伟达Quantum-X Photonics交换机交换容量达115Tb/s,支持144个800G端口;Spectrum-X Photonics更推出512个800G端口的SN6800型号,总带宽高达409.6Tb/s,支撑超大规模AI集群。
CPO模块无需单独插拔,AI工厂部署时间缩短至原来的77%(1/1.3),并显著缩短第一个 Token 的生成时间,大幅降低大规模部署的运维成本。
CPO的产业化进展:2026年量产,生态协同加速
英伟达Quantum-X InfiniBand CPO交换机预计2026年初上市,Spectrum-X以太网CPO交换机将于2026年下半年推出,均采用液冷散热设计,适配高密度、高功耗的AI工厂环境。
CPO的核心是集成硅光引擎,英伟达通过“硅光芯片+ASIC共封装”,实现电信号损耗从传统的22dB降至4dB,信号完整性提升64倍。
英伟达联合光模块、光纤、散热厂商构建CPO生态,保障大规模量产能力与可靠性。
光模块——AI算力传输的“神经中枢” 从Scale-Up对“低时延高可靠”的极致追求,到Scale-Out对“高扩展广兼容”的规模化诉求,光模块的技术演进始终以“场景需求”为核心;而CPO技术的突破,更将光互连从“功能组件”升级为“架构效能赋能者”。未来3年,224G速率的普及、LPO/NPO的规模化应用、CPO的量产落地,将共同支撑AI算力集群向“更高密度、更低功耗、更大规模”迈进,成为AI革命的关键基础设施支撑。

公众号


电话

需求反馈
