



















咨询服务热线:400-0698-860
邮箱:info@chaoqing-i.com
业务中心 - 上海超擎数智科技有限公司:上海市徐汇区龙启路158号1幢灿星大厦19层1911
业务中心 - 北京超擎数智科技有限公司:北京市海淀区北三环西路99号西海国际中心1号楼907
研发中心 - 武汉超擎数智科技有限公司:武汉东湖高新区金融港二路9号联发科武汉研发中心2楼





为全面验证高性能网络与PD分离、KV Cache Offload这两项技术的性能优势与应用价值,NVIDIA、超擎数智、联想、DaoCloud、纳多德五家公司联合投入总计数千万元的设备与资源,在超擎数智高性能计算和人工智能研发测试中心开展跨厂商协作测试。本次测试旨在为业界提供权威的技术验证结果,探索推理优化的最佳实践,并为未来的大规模部署提供参考。
在《下一代推理优化技术:高性能网络驱动的PD分离与KV Cache Offload测试(上)》中,我们详细介绍了PD分离与KV Cache Offload技术及其在模型推理中显著提升推理吞吐和并发的能力,并提出了联合测试目标、测试拓扑与环境、测试设计、预期结果及数据收集与分析。
目前,PD分离与KV Cache Offload测试正在进行中,本文将进一步分析介绍测试环境、步骤与测试结果,综合呈现KV Cache Offload技术的性能表现。
测试概述
本次测试聚焦于H20 KV Cache Offload技术在大模型推理场景中的表现,采用DeepSeek-R1模型进行验证。测试数据集包含两个:
Sonnet是一个长文本数据集(常用来做长上下文测试,数据来自书籍、长文章等)
ShareGPT是一个公开整理的对话数据集,其特性是对话多、但是单条对话的 token长度相对较短,在测试中常用于模拟 短请求、大批量并发的情况。
生成不同大小的KVcache:
按Token输入长度100,1k,10k,50k,100k ,生成不同大小的kvcache
本次主要测试3个场景:
1.当H20的显存HBM装满了后,CPU的主存offload kv cache,同时测试吞吐量和TTFT(首token的时延)。
2.当H20的显存HBM装满了后,通过400G网络将溢出的kv cache offload到远端存储中,同时测试吞吐量和TTFT(首token的时延)。
3.当H20的显存HBM装满了后,通过800G网络将溢出的kv cache offload到远端存储中,同时测试吞吐量和TTFT(首token的时延)。
测试环境未启用 GDS (GPUDirect Storage),当前完成了 南北向链路下的测试,下周将继续开展 东西向链路的验证。
此外,对vLLM 与 LMCache 框架进行了参数调优,包括 EP8、pplx、FlashInfer、DeepGEMM、DeepEP 等特性。
测试拓扑
上一期已介绍过详细的物理环境,本次测试拓扑如下:
测试环境
模型:DeepSeek-R1
网络:采用NVIDIA Spectrum-X平台RoCE网络,多轮测试中网络带宽为400G/800G
GPU/硬件:超擎元景H20高性能GPU服务器
传输链路:GDS Disable(已测南北向,计划测试东西向)
测试框架:vLLM、LMCache(开启多种优化特性)
测试步骤与结果
1.基础环境准备
a.按照上述配置搭建硬件环境。
b.在所有节点上安装操作系统及必要驱动。
c.配置存储网络,确保H20与所有AFS实例之间可以通过NVMe-oF协议通信,且网络性能达标。
d.部署并初始化存储系统,DisableGDS。
2.CPU Offload测试,测试三次并记录数据
使用vllm部署Deepseek-r1 cpu offloading,开启KV-Cache Offload功能,将KV Cache Offload到本地内存。
模型下载:略;
挂载模型目录:-v "/mnt/data:/models";
配置共享内存:--shm-size 10.24g;
在相同条件下运行ShareGPT和Sonnet压测脚本,记录性能数据。
3. Offloading到远程存储的SSD(400G)
在vLLM部署DeepSeek R1时,开启KV-Cache offload到远程高速存储中。
模型下载:略;
网络限制为400G
挂载模型目录:-v "/mnt/data:/models";
配置共享内存:--shm-size 10.24g;
在相同条件下运行 ShareGPT 和 Sonnet 压测脚本,记录性能数据。
4.Offloading到远程存储的SSD(800G)
在 vLLM 部署 DeepSeek R1 时,开启 KV-Cache offload 到远程高速存储中。模型下载:略;
网络限制为800G
挂载模型目录:-v "/mnt/data:/models";
配置共享内存:--shm-size 10.24g;
在相同条件下运行 ShareGPT 和 Sonnet 压测脚本,记录性能数据。
5.数据对比与分析
根据3种不同的cache_type和input_len,分别跑3次iteration,同时将3次iteration的结果做了平均处理。
以cache_type做划分,突出不同offloading策略的性能差异:
a.首次Token的平均时间(图表1):
此折线图展示了三种offloading策略(cpu-cpu, disk-400g, disk-800g)在不同输入长度(100、1000、10000、50000、100000 Token)下的首次Token平均时间(mean_ttft_ms,单位:毫秒)。
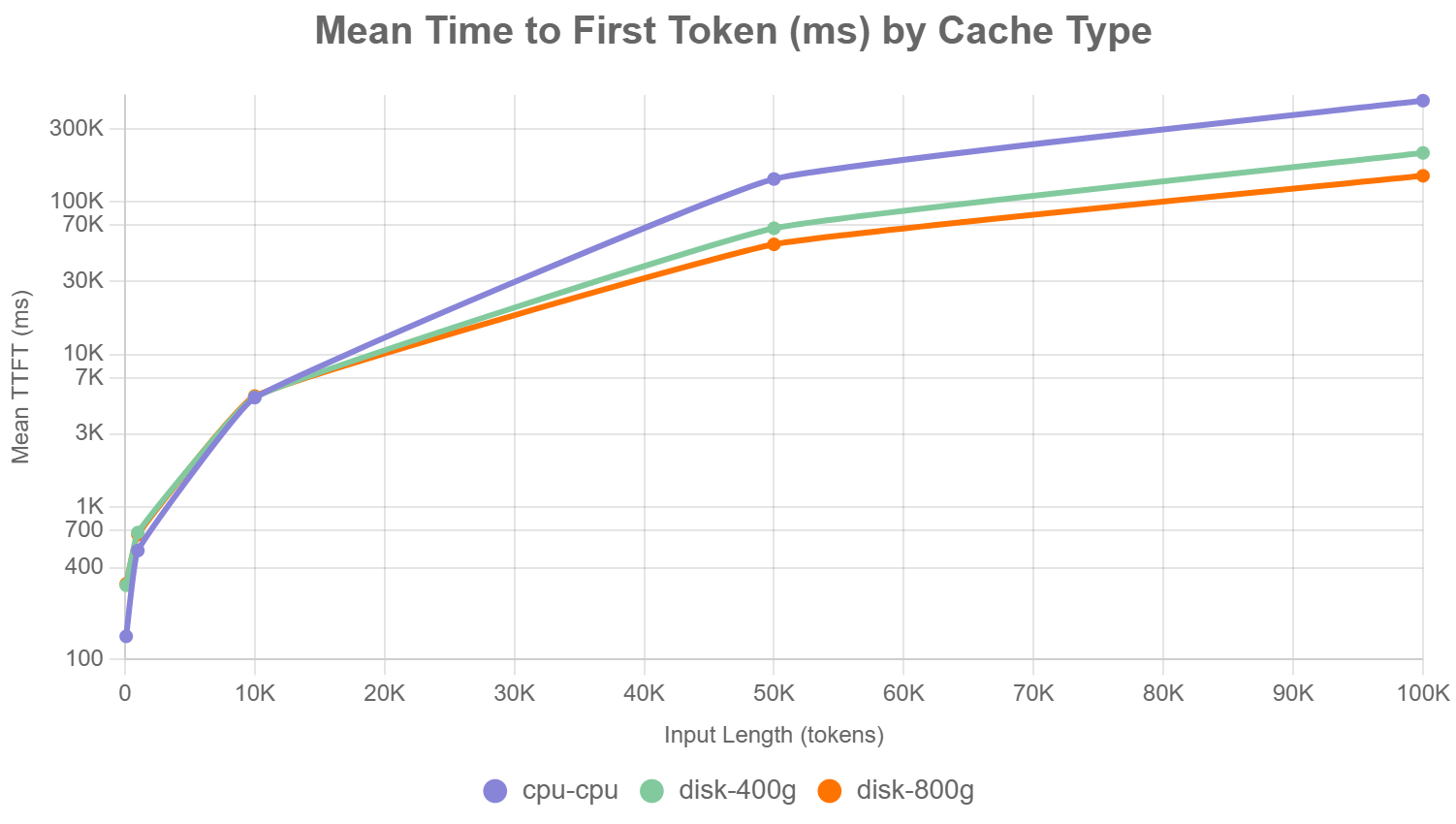
▲图表1
b.首次Token时间标准偏差(毫秒)(图表2):
此折线图展示了三种offloading策略在不同输入长度下的首次Token时间标准偏差(std_ttft_ms,单位:毫秒)。
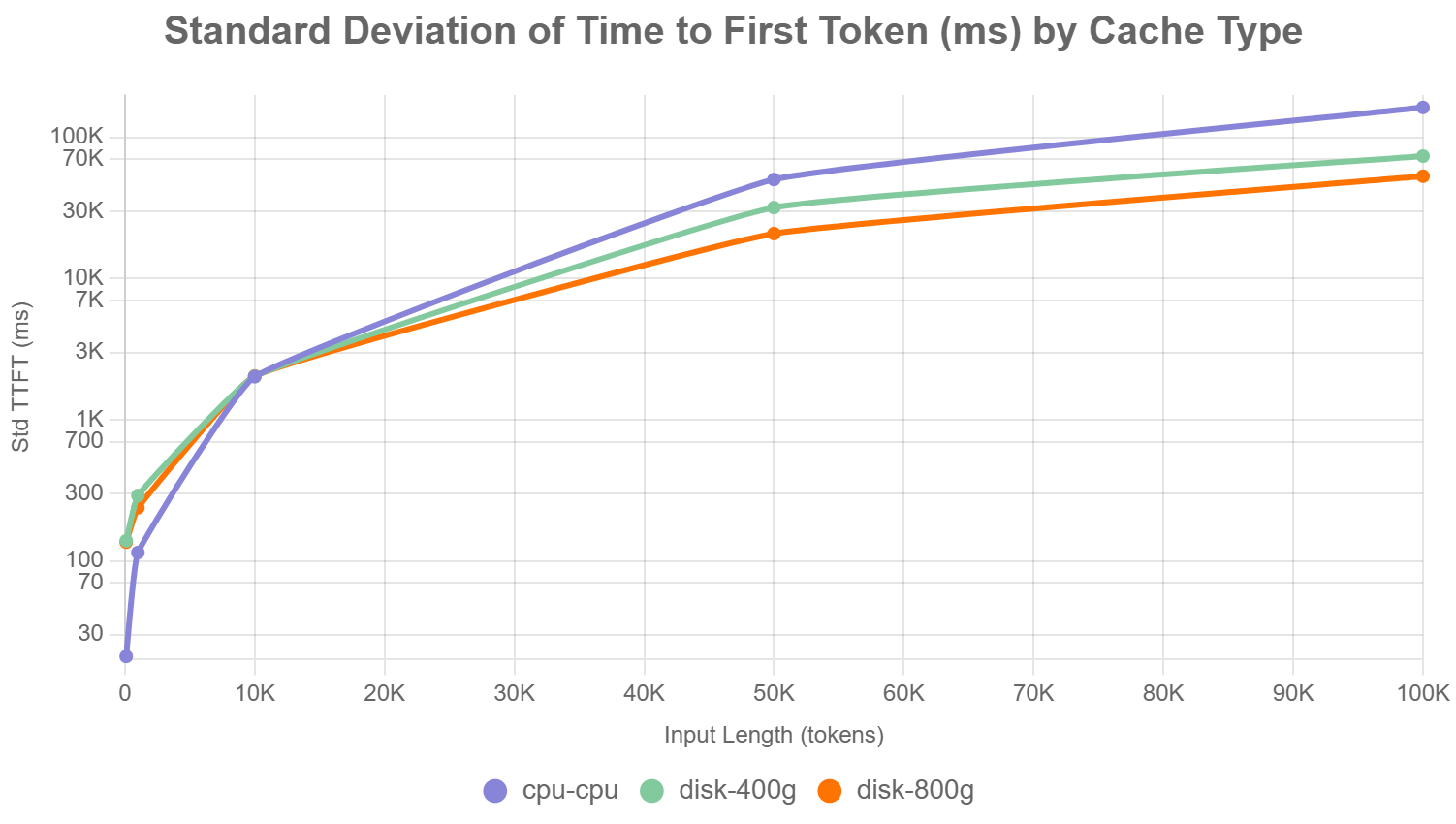
▲图表2
c.总Token的吞吐量(Tokens/second)(图表3):
展示了三种offloading策略在不同输入长度下的总Token吞吐量(total_token_throughput,单位:token/秒)
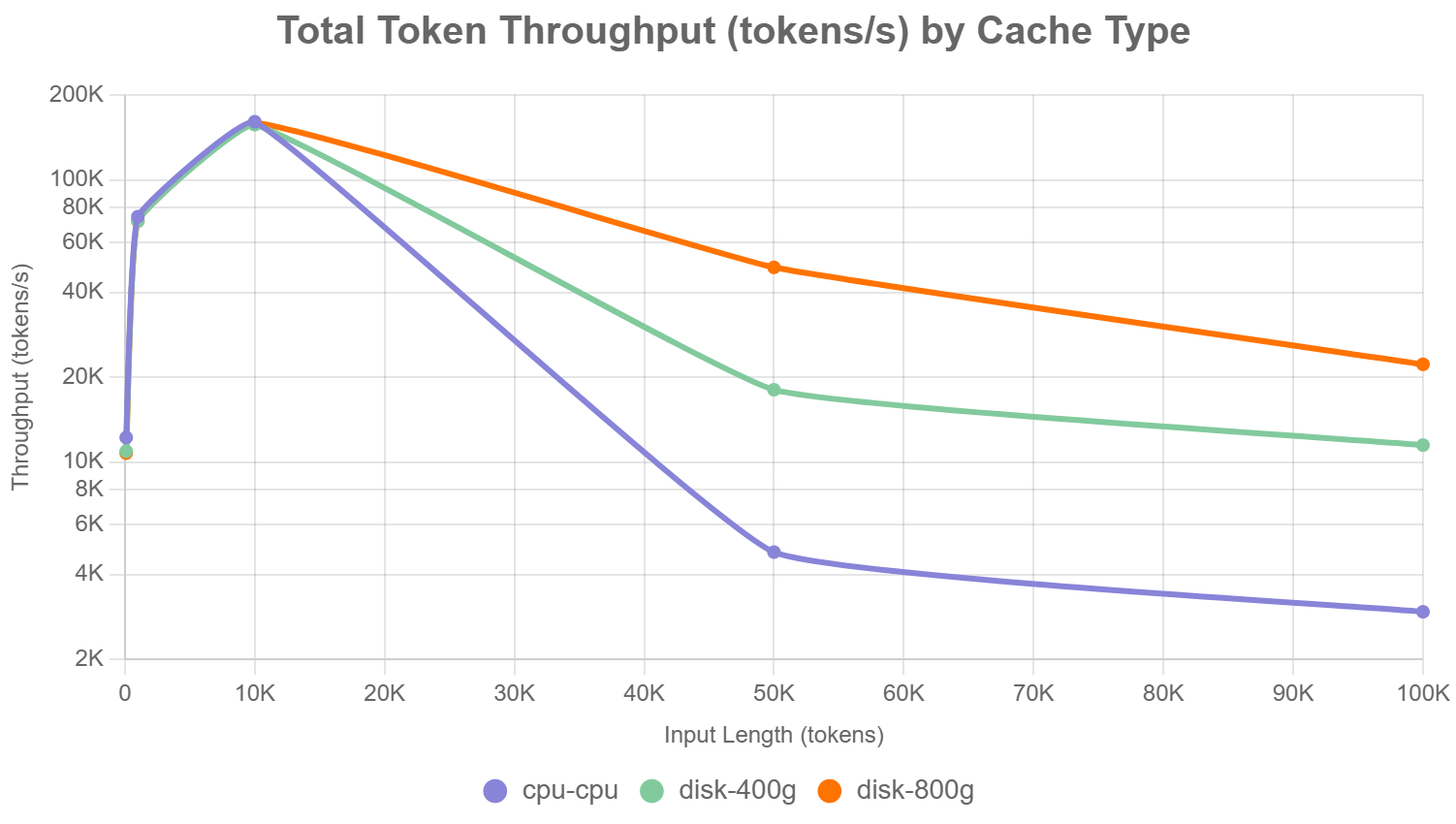
▲图表3
通过上述的实验我们可以发现,随着输入长度的增加,kvcache所缓存的数据也逐步增大,从TTFT(首Token延迟)的角度看,10K左右以下的输入Offload到内存中延迟要小于通过网络offload到存储服务器中,随着输入超过10K,通过网络offload到存储服务器的延迟开始低于offload到内存(达到内存缓存的极限同时多个内存页被swap到GPU服务器的本地磁盘中且不断的来回replace),同时网络带宽的增大对TTFT延迟有显著的降低。
将目光放到Token吞吐测试中我们了解到在输入大于10K的这个节点后通过网络offload kv cache到远端存储的token吞吐量要大于offload到本地(原因和TTFT测试一样),同样的带宽的增大对token吞吐量成正比上升。

公众号


电话

需求反馈
