



















咨询服务热线:400-0698-860
邮箱:info@chaoqing-i.com
业务中心 - 上海超擎数智科技有限公司:上海市徐汇区龙启路158号1幢灿星大厦19层1911
业务中心 - 北京超擎数智科技有限公司:北京市海淀区北三环西路99号西海国际中心1号楼907
研发中心 - 武汉超擎数智科技有限公司:武汉东湖高新区金融港二路9号联发科武汉研发中心2楼





随着今年Deepseek的爆火出圈,很多概念被大众广泛熟知,例如模型精度,模型精度是衡量机器学习模型性能的重要指标之一,不同的精度类型和评估指标可以帮助我们更全面地了解模型的表现,模型精度也直接影响着模型的性能、效率和资源消耗。
FP8(8位浮点数)和FP4(4位浮点数)是近年来在人工智能,特别是大模型(LLM)推理和训练中炙手可热的前沿技术,本文将为您详细介绍FP8和FP4两个低精度计算如何点燃AI新纪元。
什么是FP8?
FP8在计算机中本质上就是使用8个bit去表示浮点数,然后存储在GPU显存/主机内存/硬盘等地方,换句话说就是用8个二进制数字表示浮点数然后存储,FP8标准与FP16,FP32不同,是IEEE754定义的标准浮点数表示方式,因此FP8有多个表示方式,比如NVIDIA/Arm/Intel对于FP8有2种方案,分别是E4M3、E5M2,对于上周DeepSeek所提到的UE8M0 FP8方案,早在2023年OCP组织发布的Microscalingv1.0标准中就已提出。
为什么浮点数在AI中这么重要?
从模型本身的角度来讲,一个模型比如DeepSeek-R1有671B个参数,无论是训练和推理我们要先给671B个参数存储到计算机中,每一个参数我们需要使用计算机的方式进行存储,即每个参数使用FP8等格式进行存储到计算机中,每个参数从本质来讲就是一个小数,小数存储到计算机中需要使用FP8等浮点数格式进行存储。
从训练的角度来讲,每一轮训练需要使用梯度去更新模型参数,但是梯度本质上也是一个小数,既然是小数,在计算机中也需要FP8等格式进行存储传播。
为什么要用FP8?
FP16和FP32等存储格式,FP16是使用16个bit表示单个浮点数,FP32是使用32个bit表示单个浮点数,FP16和FP32是IEEE定义的标准协议,它并不是原生服务于AI应用,而是通用应用,因此如果使用原生的FP16进行训练推理,会带来非常多问题,因此在2018年Google提出了BF16用于自己的TPU上,从单个模型参数的存储空间上来说,BF16和FP16都是16个bit,但是BF16牺牲了精度而增加了范围,增加范围有什么好处?在反向传播时如果梯度太大那么会超出FP16的原生表示范围,就会减慢训练速度,浪费大量的计算资源,如果像BF16一样牺牲精度增加浮点数表示范围,就不会像FP16这样大量出现0或者N/A的梯度,从而保证训练的稳定性。
上节有讲到FP8相较于BF16/FP16采用8个bit存储浮点数,如下图:

图中我们可以清楚看到一个小格子代表一个bit,我们通过数格子的方法可以发现FP8占有8个bit,BF16/FP16占有16个bit,更进一步说明在BF16/FP16下,我们需要16个bit(2个字节)存储模型的一个参数,在FP8格式下我们只需要8个bit(1个字节)来存储模型的一个参数,意味着一个相同大小的模型(假如671B个参数)如果使用FP8格式存入GPU中所消耗的空间大小只有FP16/BF16的一半。
FP8不仅将显存占用减半,更大幅降低了功耗、提升了计算速度,更关键的是,它使得在边缘设备上部署更大模型成为可能。
超擎数智作为领先的人工智能核心产品与整体解决方案提供商,在FP8和BF16两种精度模型下做过大规模对比训练测试,整个测试使用640张L20 GPU,通过IB网络互联,整个方案设计与组网,集群搭建都是由超擎团队完成,测试持续一周,整个训练的收敛测试如下图,橙色代表BF16, 蓝色代表FP8,总的来说2个模型训练时的收敛路径基本一致,FP8在训练中Loss基本平滑,不会有梯度爆炸等情况出现。
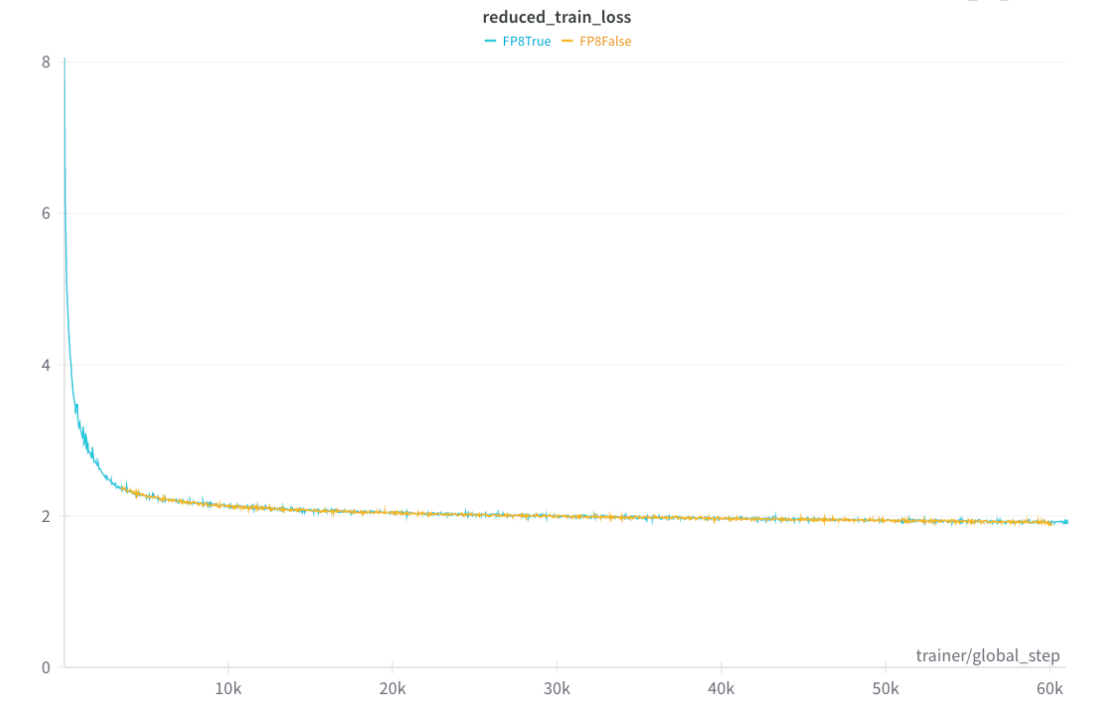
从训练性能来讲,FP8所消耗的训练时间更短,token的吞吐量更大。

使用FP8的优势:
使用FP8的痛点:
UE8M0FP8是什么?
上周DeepSeek提到的DeepSeek V3.1因采用了一种特殊的UE8M0 FP8方案进行训练而引发热议。
首先需要说明的是,FP8并没有像IEEE 754那样的统一国际标准,目前业内存在多种变体,例如常见的E4M3、E5M2,以及DeepSeek提到的 UE8M0。
从名字可以看出,UE8M0表示Unsigned Exponent 8 Mantissa 0,但与传统浮点数格式不同,UE8M0并没有严格的“指数/尾数”划分,它实际上就是8位无符号整数(0–255)+ 动态缩放因子,其中 U 表示只支持非负数。
与 E5M2 这类标准 FP8 格式相比,UE8M0 的表示方式极大地简化了,它不再内置指数和尾数,而是依赖一个外部的缩放因子 2^{-s} 来扩展表示范围,比如在训练中可以为一个矩阵,甚至为矩阵的每一行指定不同的缩放因子,从而覆盖不同数值范围。
在硬件实现上,这种方案的优势非常明显:由于 UE8M0 仅仅是整数 * 缩放因子,不需要实现完整的浮点加减/规格化逻辑,GPU的计算单元只需支持整数运算和简单的位移,这使得硬件设计更为高效,能耗更低,非常适合大规模AI训练和推理场景。
总结:
什么是FP4?
除了FP8以外,是否还有显存空间消耗更小的方案呢?其实FP4也早已提出,在NVIDIA最新的Blackwell架构GPU中已经支持FP4功能,同样的FP4目前也是厂家制定的标准,当前的Blackwell架构支持2种FP4格式分别是MXFP4与NVFP4,这两种方案有什么区别?
首先他们的存储浮点数的方式都是E2M1,但是MXFP4是32个FP4值共享一个缩放因子,而NVFP4是16个FP4共享一个缩放因子,NVFP4有更细的颗粒度控制,同时NVFP4和MXFP4的缩放因子也不同,他们的关系总结如下:
缩放因子可以参考UE8M0,本质上除了显存本身存储的浮点数外,乘以一个缩放因子可以使FP8/FP4表示小数或者扩大表示范围。

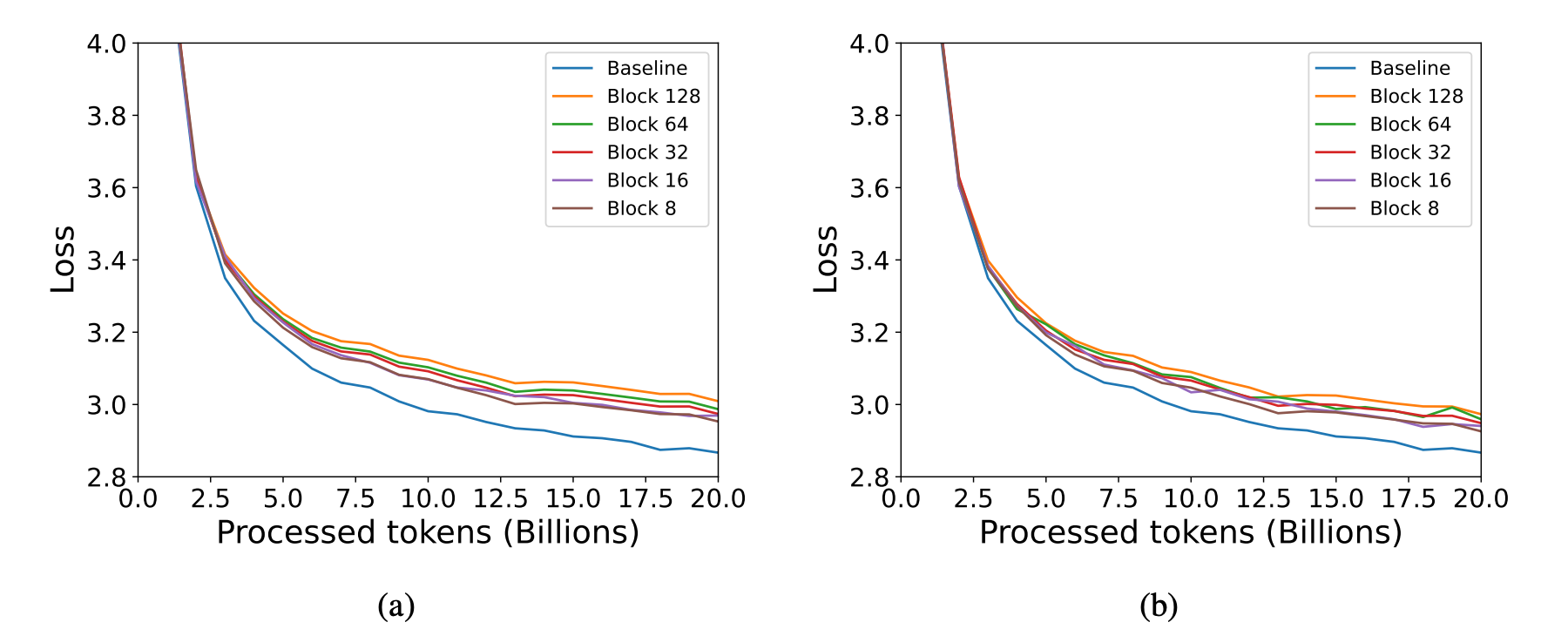
从上图的测试中我们可以看到,无论是图a(MXFP4)还是图b(NVFP4),都是block内存放的FP4值越少,模型的训练收敛越快,同时代表训练速度越快,但是block内的FP4越少代表需要耗费更多的存储空间去存缩放因子,归根结底成为了一个空间换时间还是时间换空间的问题。
一个block内部的FP4值共享一个scale缩放因子。
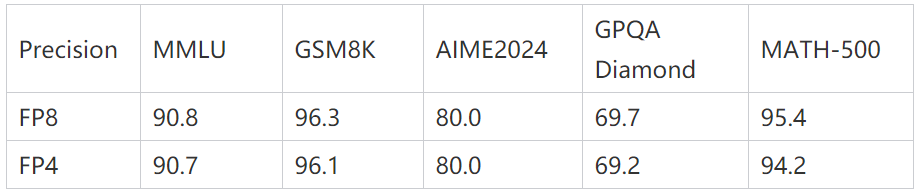
当然有不少的人会关心,相同模型FP8和FP4他们问答的准确度是否有下降,在上个月NVIDIA对原DeepSeek-R1671B模型(fp8精度)做量化推出了DeepSeek-R1671BFP4版,在一些专业问题测评方面FP4相较于FP8只有非常少的衰减,测评分数如下:
总结:
回顾从 FP32 向 FP4 的演进历程可以发现,未来的发展趋势必然是模型精度持续降低。但需要强调的是,更低精度并非开箱即用,在训练与推理中如何充分发挥 FP8 与 FP4 的优势、克服其局限,才是技术发展的关键。
超擎数智以AI应用全栈方案赋能千行百业智能化转型,提供领先的GPU服务器与AI加速平台,更能在以下方面助力客户业务加速发展:

公众号


电话

需求反馈
