



















咨询服务热线:400-0698-860
邮箱:info@chaoqing-i.com
业务中心 - 上海超擎数智科技有限公司:上海市徐汇区龙启路158号1幢灿星大厦19层1911
业务中心 - 北京超擎数智科技有限公司:北京市海淀区北三环西路99号西海国际中心1号楼907
研发中心 - 武汉超擎数智科技有限公司:武汉东湖高新区金融港二路9号联发科武汉研发中心2楼





近年来,大规模模型在各类应用场景中快速落地,带动了推理需求的高速增长。随着模型参数量不断提升和用户请求并发数持续攀升,如何提升推理性能成为业界关注的核心问题,在众多优化方向中,PD分离与KV Cache Offload被认为是当前对推理性能提升最具突破性的两项关键技术,前者通过计算与通信解耦,实现更高效的资源利用,后者则通过缓存卸载,极大降低了显存占用并提升大模型长文本推理的效率。
为全面验证高性能网络与PD分离、KV Cache Offload这两项技术的性能优势与应用价值,NVIDIA、超擎数智、联想、DaoCloud、纳多德五家公司联合投入总计数千万元的设备与资源,在超擎数智高性能计算和人工智能研发测试中心开展跨厂商协作测试。本次测试旨在为业界提供权威的技术验证结果,探索推理优化的最佳实践,并为未来的大规模部署提供参考。
在大模型推理场景中,传统架构面临两大挑战:
PD分离(Prefill & Decode Separation)与KV Cache Offload是当前大模型推理中的核心优化技术,可显著提升推理吞吐和并发能力:
PD分离与KV Cache Offload技术介绍
在大语言模型(LLM)的推理过程中,通常会经历两个阶段:
1)Prefill阶段(输入处理)
a.模型一次性读取并并行处理全部输入Token,建立上下文理解
b.计算模式:高并行度的矩阵乘法,计算密集,显存占用相对较低
c.特点:更适合高吞吐量的GPU、多卡并行运行
2)Decode阶段(输出生成)
a.模型基于上下文(以及 KV Cache)逐个生成Token
b.计算模式:顺序生成,一个Token接一个Token,延迟敏感
c.显存占用:会随着上下文长度增长而迅速增加(因为要存KV Cache)
在传统部署中,这两个阶段通常运行在同一批GPU上。但问题是Prefill和Decode的资源需求完全不同——一个追求高并行算力,一个追求低延迟和大显存。把它们混在同一批GPU上跑,往往两边性能都打折扣。
PD分离(Prefill–Decode Separation)
顾名思义,就是把Prefill和Decode分开部署在不同的硬件资源池中:
这样做的好处:
PD分离的基本框架:
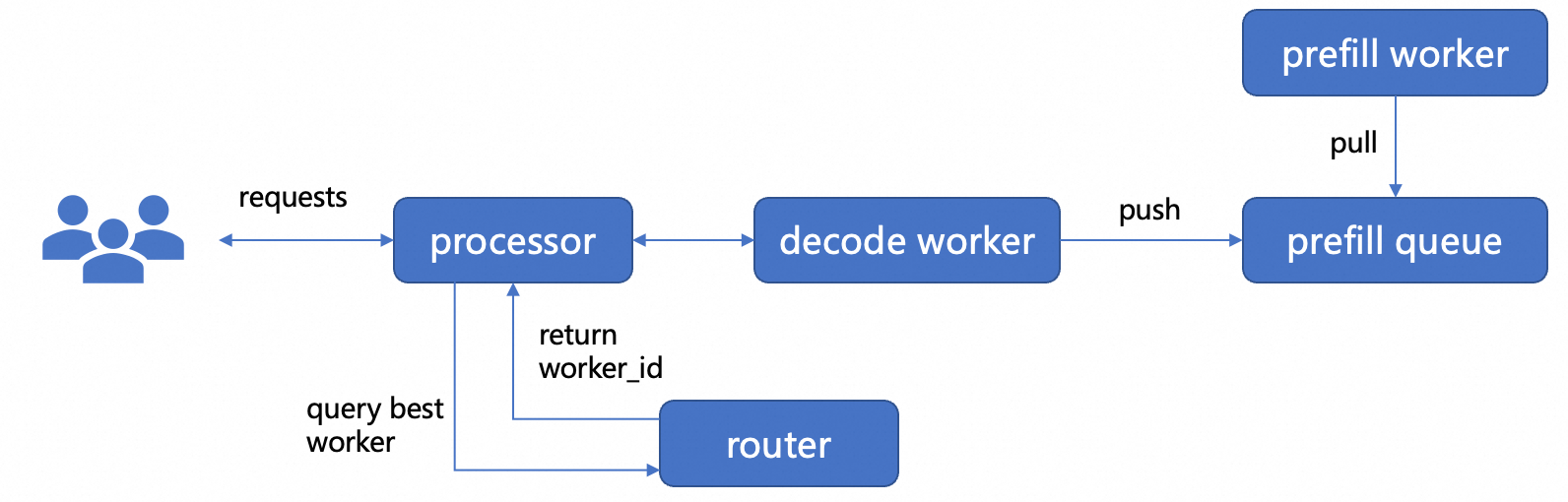
PD分离的挑战
如果Prefill和Decode放在不同的GPU上,需要传输KV Cache,网络延迟和带宽会成为瓶颈。
系统要实时协调两列任务的分配,否则Decode阶段可能会空等Prefill的结果,或者Prefill资源被Decode阻塞。
框架和任务调度器需要支持流水线,KV Cache输出,异步执行等操作,难度要比单机单卡推理更难维护。
Prefill阶段可能会同时处理多个请求,Decode阶段需要保留全部的KV Cache,内存压力会很大。
PD分离就是“分工合作”,让Prefill和Decode各自使用最适合的GPU,从而提升效率和吞吐量,但也需要解决通信、调度、内存等方面的挑战。
如果把大语言模型(LLM)比作一个写小说的作家,那么Transformer就是他的“思考方法”。
作家写故事时,会一边看之前写的内容,一边决定接下来写什么。同样,Transformer 在生成文本时,也是一边参考之前生成的Token,一边预测下一个Token。
从Transformer说起
在Transformer的自注意力(Self-Attention)机制里,每个Token(可以理解为一个词或字的编码)都会生成三种向量:
在Transformer生成文本时,每次只会生成一个新Token,模型会用这个Token的Q去和所有历史Token的K做匹配,找到相关性,然后用这些相关的V计算输出,但是标准Transformer在推理时是逐个Token生成的,比如:
输入:“我想要读一”
生成:“我想要读一本”
继续生成:“我想要读一本书”
但在生成第三个Token时,它又会重新计算前面所有Token的K和V,哪怕这些数据早就算过了!
这种重复计算会导致推理的计算量随着Token数量呈二次方增长,速度很慢。
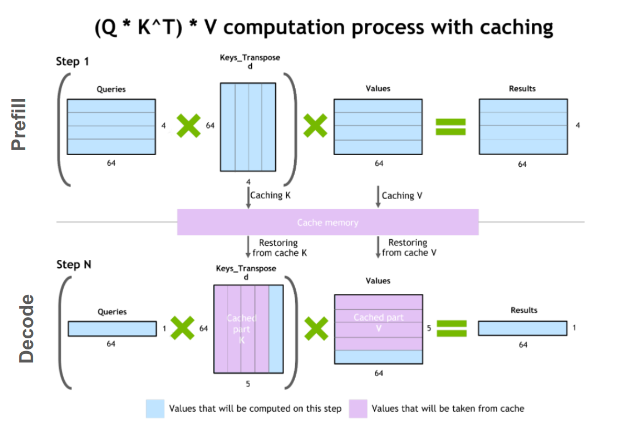
KV Cache的核心宗旨"别重复干活"
KV Cache的核心思想是:历史的K和V早就算好了,直接存起来,别每次都重算。
这样,每次生成新Token时,只需:
这样一来,推理的计算量就从二次方降到线性,大大加快速度。
为什么要Offload
KV Cache虽然能加速,但它有个副作用:特别占显存。
举个例子:
显存是GPU上最宝贵的资源,除了KV Cache,还需要存模型权重、中间计算结果等。如果显存被占满,推理就会崩溃或者无法运行。
Offload 的作用
Offload就是把一部分数据从显存(GPU Memory)挪到其他存储介质,比如:
在KV Cache场景下,Offload的好处是:
联合测试概述
验证PD分离和KV Cache Offload在大模型推理场景下的性能优化效果,具体包括:
2.测试拓扑与环境
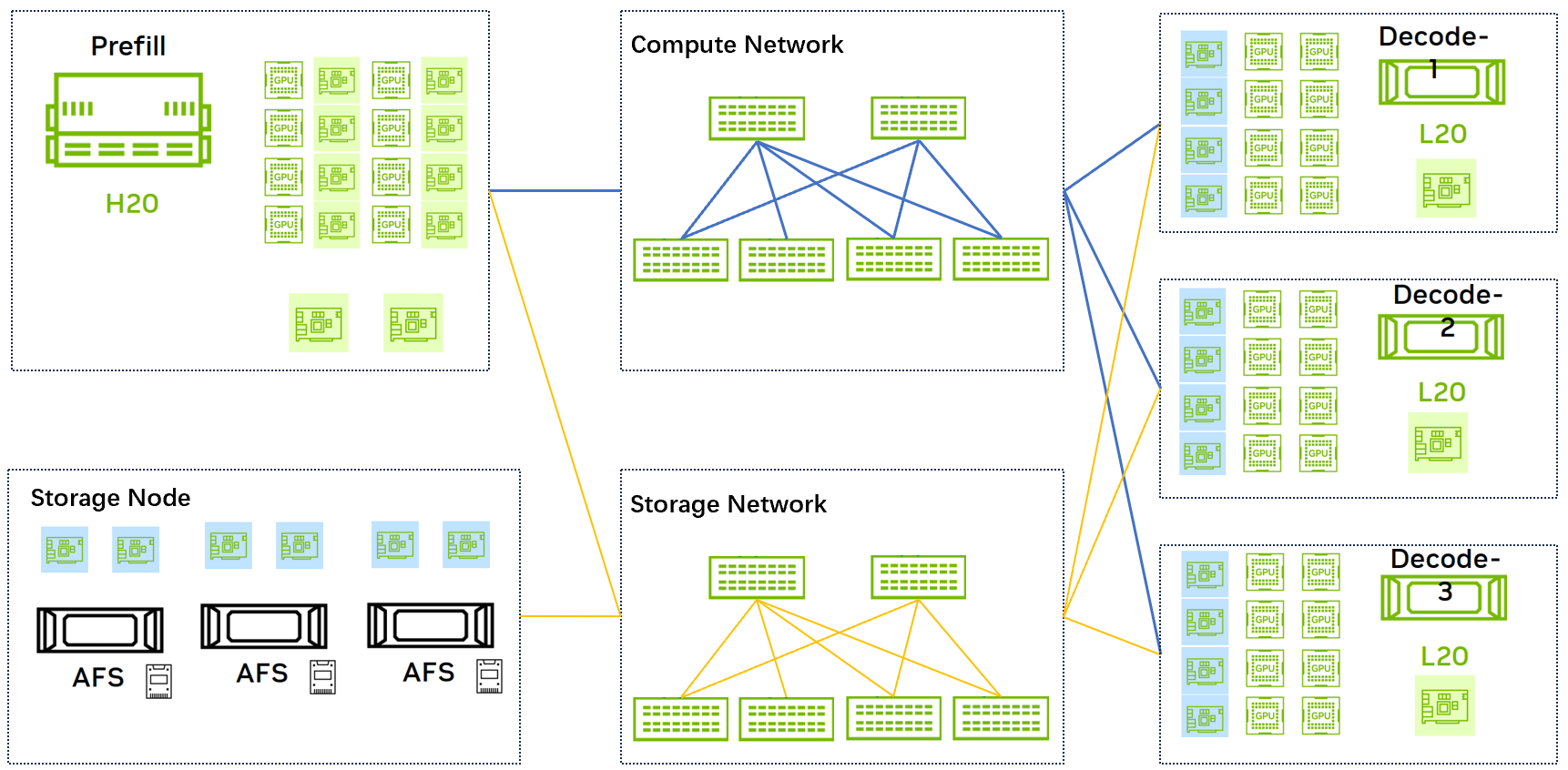
图1:测试拓扑图
测试拓扑见上图,环境信息如下:
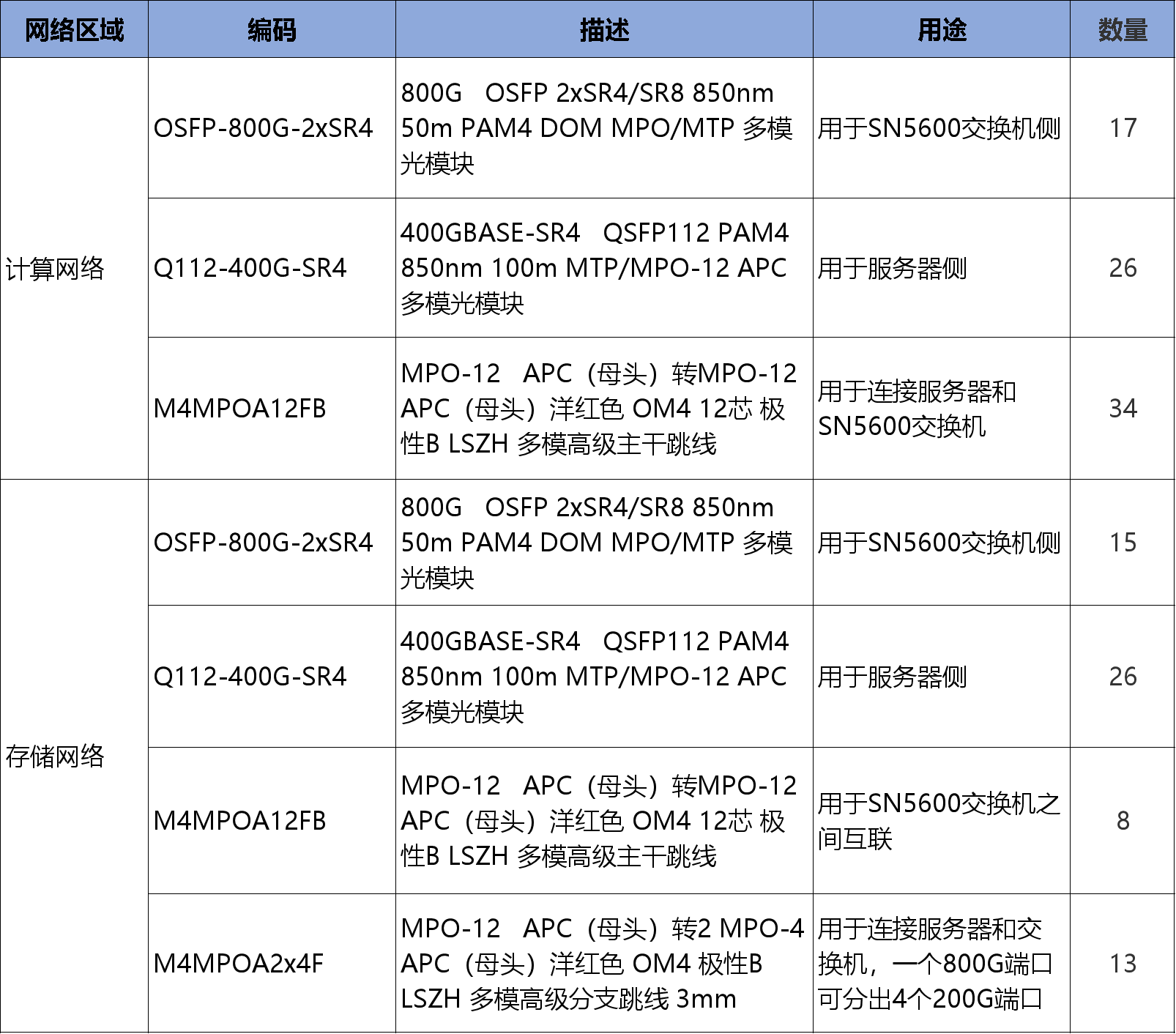
关键组件如下:
3.测试设计
3.2 KV Cache Offload测试
验证PD分离与Offload协同效果:
预期结果:
预期结果:
预期结果:

公众号


电话

需求反馈
