



















咨询服务热线:400-0698-860
邮箱:info@chaoqing-i.com
业务中心 - 上海超擎数智科技有限公司:上海市徐汇区龙启路158号1幢灿星大厦19层1911
业务中心 - 北京超擎数智科技有限公司:北京市海淀区北三环西路99号西海国际中心1号楼907
研发中心 - 武汉超擎数智科技有限公司:武汉东湖高新区金融港二路9号联发科武汉研发中心2楼





在AI大模型加速落地的过程中,企业越来越关注一个现实问题:同样的GPU配置,如何在真实业务负载下获得更稳定、更健康、更高效的性能表现?
对于AI高效推理而言,算力并不只是由GPU型号决定。尤其在多卡大模型推理场景中,要实现持续、稳定、高效的Token输出,服务器内部的系统级设计至关重要。
如果服务器设计不当,就可能导致推理性能抖动、Token吞吐下降、首Token延迟和单Token延迟不稳定,最终影响客户侧AI应用的响应速度、并发能力和服务稳定性,甚至造成用户体验下降、业务请求超时、推理成本上升等问题。
近期,超擎数智技术团队基于自研的擎天CQ7458-L AI服务器(支持8卡)搭配4 × RTX PRO 5000 72GB GPU开展了不同风扇模式下的AI推理测试,旨在模拟客户的真实推理落地场景,对机器稳定性、Token吞吐等方面进行全方位测试对比。
本次测试不是单纯的参数展示,而是一次面向真实AI工作负载的严谨验证。它体现了超擎数智在AI服务器调优、推理框架适配、技术策略验证和工程化交付服务方面的综合技术能力。
1、测试背景:AI服务器性能释放,离不开系统级调优
随着企业本地化部署大模型的需求快速增长,推理服务与轻量化微调正在成为AI基础设施中的高频场景。
一方面,vLLM等高性能推理框架被广泛用于大模型服务化部署,企业希望在有限硬件资源下获得更高token吞吐、更低首Token延迟和更稳定的并发响应能力。
另一方面,PEFT LoRA等参数高效微调方式,正在帮助企业以更低成本完成模型适配,让大模型更好地服务于垂直业务场景。
在这类场景中,RTX PRO 5000 72GB的高显存配置为31B级别大模型推理提供了重要硬件基础,但GPU能力能否持续稳定释放,还取决于服务器整机平台的散热、供电、驱动、框架和并行配置。
因此,企业在选型AI服务器时,不仅要看GPU参数本身,更要关注GPU在真实模型任务中的持续运行能力,以及整机平台能否帮助其稳定释放推理性能。
2、测试平台:基于超擎数智擎天服务器开展验证
本次测试基于超擎数智擎天系列CQ7458-L AI服务器进行,核心计算平台采用4 × RTX PRO 5000 72GB GPU,配置如下:
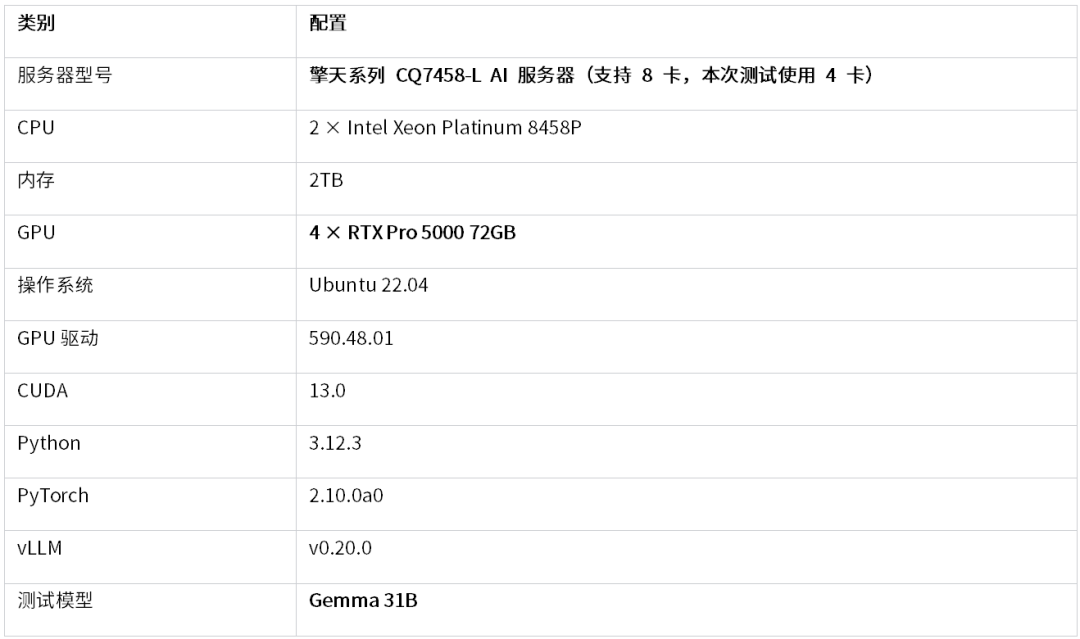
该配置更贴近企业在本地部署中大模型推理的典型需求,也有助于验证RTX PRO 5000 72GB在多卡并行、模型加载、显存占用、推理吞吐和长时间运行中的综合表现。
3、测试方法:对比不同风扇策略下RTX PRO 5000的表现
本次测试重点对比两种风扇模式:
Balance 模式
即服务器采用相对平衡的风扇策略,在散热、噪音和功耗之间保持默认调节。
最大转速模式
即通过BMC将风扇调整至手动满速状态,以最大化散热能力,观察GPU在更充分散热条件下的推理性能表现。
测试过程中,技术团队同步监控GPU温度、功耗、频率、显存占用和利用率等关键指标,并使用vLLM bench进行推理压测。
测试参数包括:
通过统一模型、统一输入输出长度、统一并发参数的方式,测试结果能够更直观反映不同散热策略对RTX PRO 5000多卡推理性能释放的影响。
4、vLLM 推理测试结果:最大转速模式下性能表现更稳定
Balance模式测试结果
在Balance模式下,Gemma 31B推理测试结果如下:

从结果来看,Balance模式下整体推理任务可以稳定完成,50次请求均成功执行,说明平台具备良好的基础可用性。
最大转速模式测试结果
在最大转速模式下,Gemma 31B推理测试结果如下:
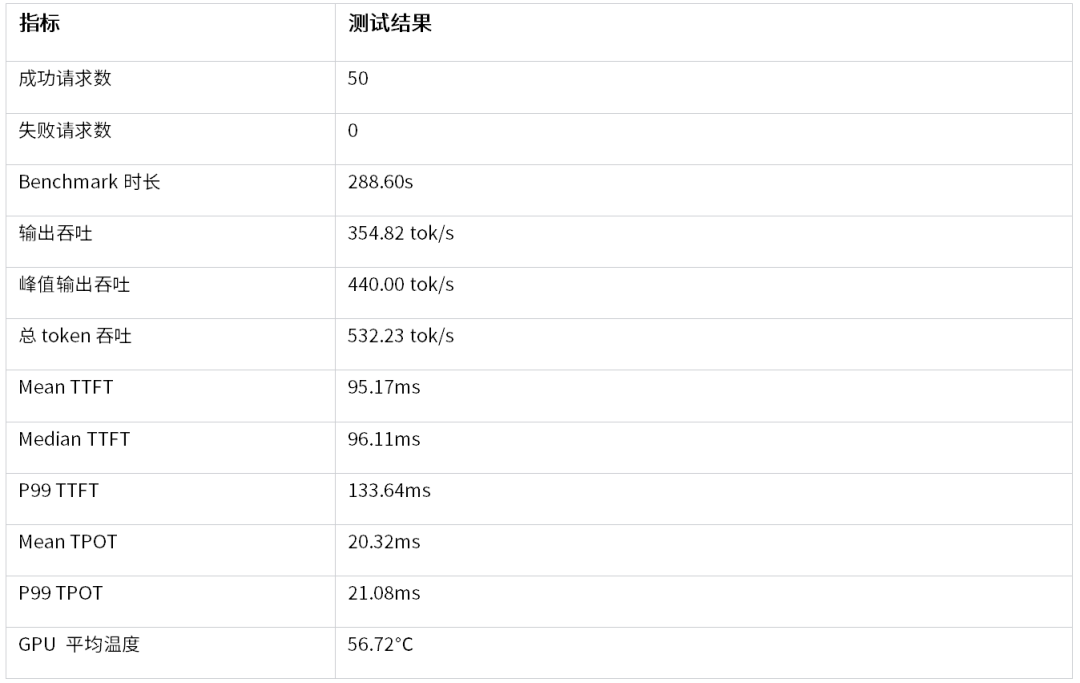
相比Balance模式,最大转速模式下整体推理表现更加稳定:
在本次测试环境下,最大转速模式使输出吞吐提升约2.8%,总token吞吐提升约2.8%。更值得关注的是,首Token延迟表现明显优化,P99 TTFT大幅下降,GPU平均温度对比下降18.59℃,体现出RTX PRO 5000在充分散热条件下具备更好的响应稳定性。
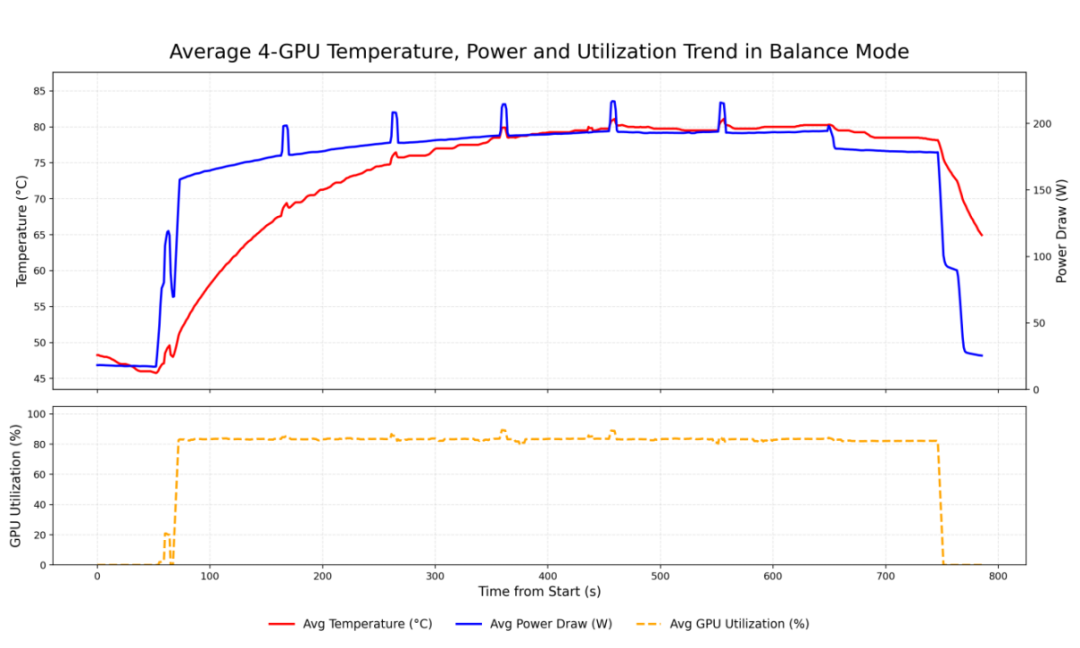
banlance模式下4张GPU的平均温度、GPU使用率、功耗对比
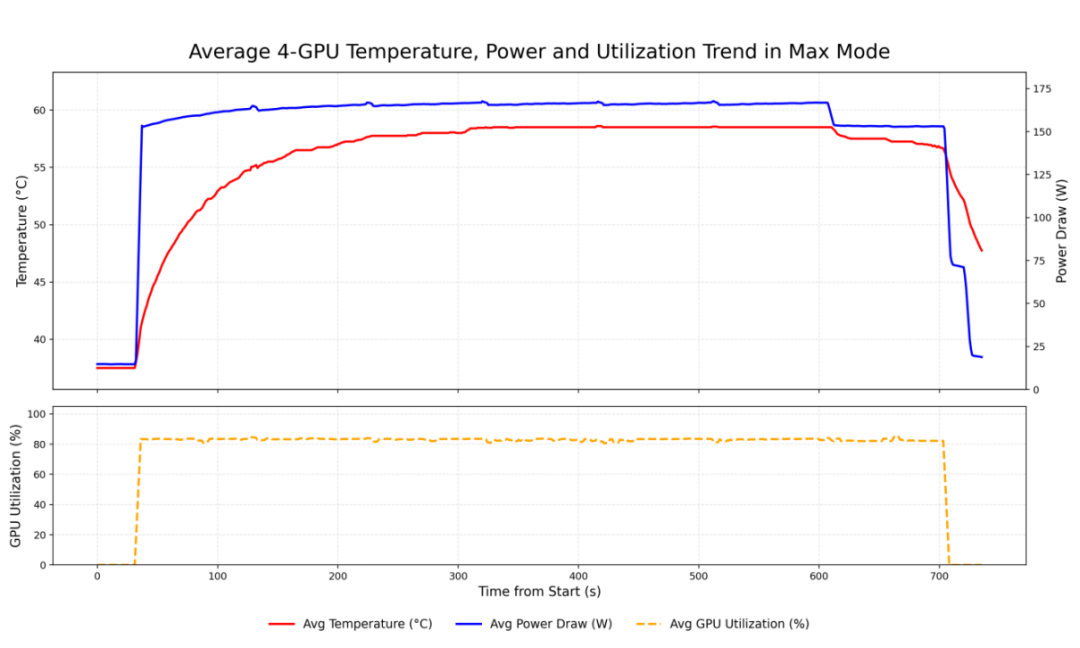
max模式下4张GPU的平均温度、GPU使用率、功耗对比
这表明,在高负载大模型推理场景中,充分释放散热能力,有助于提升GPU频率稳定性和请求响应一致性,从而改善整体推理体验。
5、超擎数智:不止交付软硬件一体AI全栈方案,更保障可持续运行的AI能力
本次基于实际AI推理场景的对比测试表明,RTX PRO 5000作为企业级AI推理场景中的重要算力单元,其真实性能释放并不只取决于自身参数,还与服务器的散热策略、功耗释放、软硬件适配、推理框架调优和工程化验证密切相关。
在相同硬件、模型、框架和并发参数下,最大转速模式相较Balance模式展现出更稳定的推理表现,尤其在首Token延迟和P99 TTFT指标上改善明显。这说明在高负载、低延迟敏感型大模型推理场景中,合理的整机散热与系统调优,能够进一步释放GPU的性能潜力。
更重要的是,本次测试也体现出超擎数智围绕高性能GPU、AI服务器开展系统级调优和真实业务验证的能力。AI高效推理实际落地不是单一硬件参数能够覆盖的问题,而是需要从整机平台、软件栈、模型任务和运维服务多个层面协同优化。
面向企业AI基础设施建设需求,超擎数智不仅提供设备部署,更能够围绕模型规模、并发需求、训练与推理场景,提供从方案设计、环境部署、性能测试、参数调优到长期运维的全流程支持。从“交付设备”到“提供可运行、可验证、可持续优化的AI能力”,正是超擎数智的重要优势。
随着AI从实验室走向生产场景,企业对基础设施的要求也正在从“有没有算力”转向“算力能否稳定释放、能否支撑业务长期运行”。未来AI基础设施的竞争,将不只是硬件参数的竞争,而是系统级技术能力、工程化交付能力和持续服务能力的竞争。超擎数智将持续围绕算力、网络、存储进行深度融合,帮助企业构建更加稳定、高效、可持续演进的AI算力底座。

公众号


电话

需求反馈
