



















咨询服务热线:400-0698-860
邮箱:info@chaoqing-i.com
业务中心 - 上海超擎数智科技有限公司:上海市徐汇区龙启路158号1幢灿星大厦19层1911
业务中心 - 北京超擎数智科技有限公司:北京市海淀区北三环西路99号西海国际中心1号楼907
研发中心 - 武汉超擎数智科技有限公司:武汉东湖高新区金融港二路9号联发科武汉研发中心2楼





在AI算力爆发的今天,数据中心网络正经历一场从400G到800G的带宽升级。
对于大模型训练、AI推理、云计算平台和智算中心建设而言,网络已经不再只是“连接设备”的基础组件,而是影响GPU利用率、训练效率、业务时延和整体成本的关键基础设施。
当前,51.2Tbps交换容量已经成为高端数据中心交换机的重要形态。围绕这一带宽规格,市场上主要存在两类端口设计:
一种是128×400G QSFP112,另一种是64x800G OSFP。
两者总交换容量相同,但在端口密度、单端口带宽、布线复杂度、故障影响范围、光模块成本、扩展方式和长期运维等方面存在明显差异。
对于企业而言,真正关键的问题并不是“哪一种交换机更先进”,而是哪一种网络形态,更适合当前业务负载、未来扩展路径和整体投资节奏。
作为AI原生的基础设施整体解决方案提供商,超擎数智结合一线项目经验,从实际部署视角出发,对64×800G与128×400G两种51.2T交换机形态进行系统分析,帮助企业在AI集群建设中做出更适配的网络选型决策。
一、51.2T交换机的两种主流形态
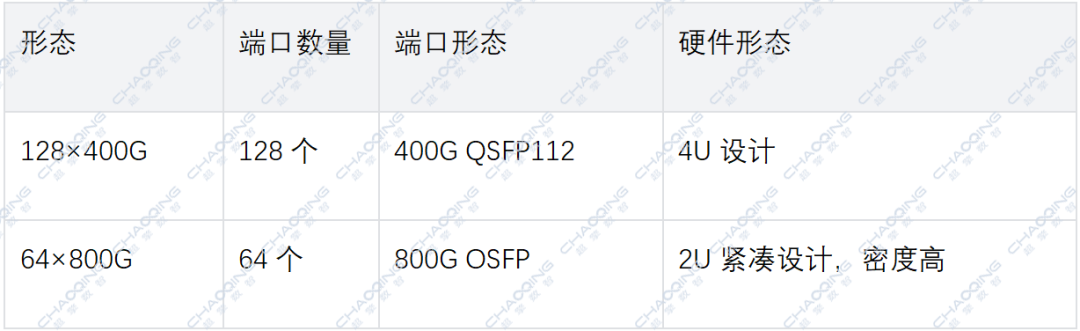
51.2T交换机包含512个SerDes以每秒100Gb的速度运行,共同构建了高达51.2Tb/秒的带宽,能够轻松应对数据中心日益增长的数据传输和处理压力。当前,基于51.2T交换芯片的交换机主要有两种形态:128 × 400G QSFP112和64 x 800G OSFP。
128 x 400G QSFP112:交换机拥有128个400G的QSFP112接口。每个接口提供400Gbps的带宽,总带宽为51.2Tbps(128 × 400G = 51,200G = 51.2T)。
这种设计的核心特点是端口数量多、连接粒度细,适合对资源弹性扩展、故障影响范围控制和现有400G生态兼容性要求较高的场景
64 x 800G OSFP:交换机拥有64个800G的OSFP接口。每个接口提供800Gbps的带宽,总带宽同样是51.2Tbps(64 × 800G = 51,200G = 51.2T)。
这种设计的核心特点是单端口带宽高、设备形态紧凑,适合大规模AI训练集群、高密度机房和对部署效率、能耗表现要求更高的场景。
它们的核心差异在于端口密度和单端口带宽的权衡,以及由此带来的部署、运维、成本等一系列连锁反应,这也是一线部署中最直观的感受。
值得注意的是,部分交换机支持端口拆分功能,可将一个800G端口拆分为两个400G端口使用,实现一定程度的形态灵活转换,兼顾两种形态的部分优势。
二、51.2T交换机的组网方式
51.2T交换机面向AI高带宽、低时延的应用场景,尤其是支持高达512个接口的扩展能力, 从而只需要两层的Spine/Leaf架构就可以支持高达数万个GPU的AI数据中心网络架构。
1、64 x 800G交换机
Leaf/Spine交换机采用64 x 800G交换机,主要搭配使用800G OSFP或QSFP-DD800光模块。根据设备之间传输距离的不同,可采用800G VR8(50m)、800G SR8(100m)、800G DR8(500m)或者800G 2xFR4 (2km)光模块来满足需求。
2、128 x 400G交换机
当Leaf/Spine交换机采用128 x 400G交换机,它们之间的互联主要搭配使用400G OSFP/QSFP112这几种封装的光模块。根据设备之间传输距离的不同,可采用400G VR4 (50m)、400G SR4 (100m)、400G DR4(500m)或者400G FR4 (2km)光模块来满足需求。
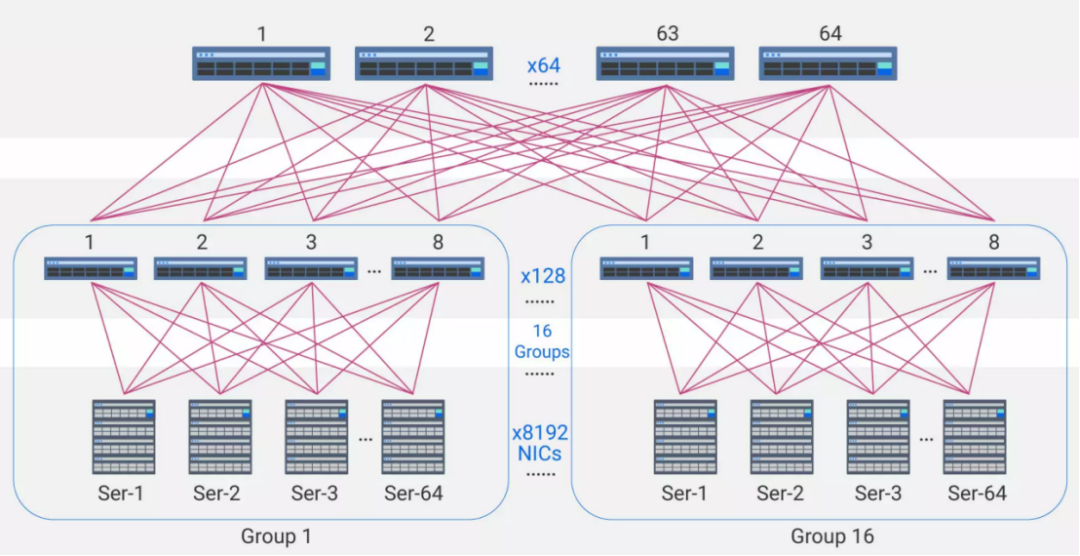
64×800G交换机组网架构
三、全面对比:两种形态的优势分析
128×400G设计在51.2T交换机中的优势
单端口故障的影响范围更小,确保AI工作负载操作的可靠性。AI工作负载运行在全天候不间断的计算平台上,设备故障的影响范围直接决定了训练任务的稳定性。128×400G设计单个400G端口故障只会影响一个GPU/AI节点,即一条400G链路,且流量可快速重路由,对整体训练任务影响较小。如果800G端口直接连接到单一节点,其故障影响范围与400G端口相同,但800G端口更高的带宽会导致故障后重路由的流量压力更大。如果一个800G端口通过拆分连接到多个节点以利用其高带宽,单个800G端口故障将影响多个计算节点,直接导致训练任务部分中断。
更细粒度的网络架构,适应AIDC网络集群的弹性扩展需求。AIDC网络集群的计算能力扩展不是一次性部署,而是分阶段的弹性扩展(例如,每次增加8/16/32个GPU节点以满足工作负载的计算需求),这是一种细粒度扩展。128×400G配置中的400G端口作为细粒度带宽单元,能够准确满足少量节点的扩展需求,同时不浪费端口资源。相比之下,64×800G配置中的800G端口是粗粒度带宽单元:如果只添加少量节点,800G端口无法被充分利用,容易导致“连接低计算能力的大端口”资源不足。
更低的光互连成本和更成熟的供应链,减少AIDC网络建设和运维成本。在AIDC网络的总成本中,光收发器DAC/AOC电缆所占比例远高于交换机本身(约60%至80%)——而128×400G配置在光互连方面具有显著的成本优势:
64×800G设计在51.2T交换机中的优势
高空间利用率与高部署效率。当前AIDC网络部署已迈入千卡级、万卡级大规模GPU集群时代,随着智算集群规模持续扩容,AIDC场景对机房空间资源利用率与整体部署交付效率提出了更高要求。在此背景下,高带宽、高密度端口架构设计在实际AIDC工程落地与规模化组网部署中具备显著优势,同时适配AI大模型训练、智算算力调度等高吞吐、低时延的业务诉求,为大规模GPU集群的高效组网、快速上线与长期平稳运行提供坚实网络底座支撑:
功耗与散热效率。64×800G设计依托高密度集成架构,在整机基底功耗、端口器件功耗、风道散热效率、机房配电承载及AIDC数据中心PUE适配层面具备系统性优势。首先在硬件基底功耗上,有源器件数量更少,整机空载静态功耗显著更低,从硬件架构根源压缩基础能耗;虽然单只800G光模块功耗高于单颗400G模块,但整机仅需配置64个光口,远少于128×400G的128端口满配规模,整机光模块聚合总功耗反而更低,避免多端口堆叠带来的功耗累加浪费。
以搭载Broadcom TH5的某两款交换机为例:
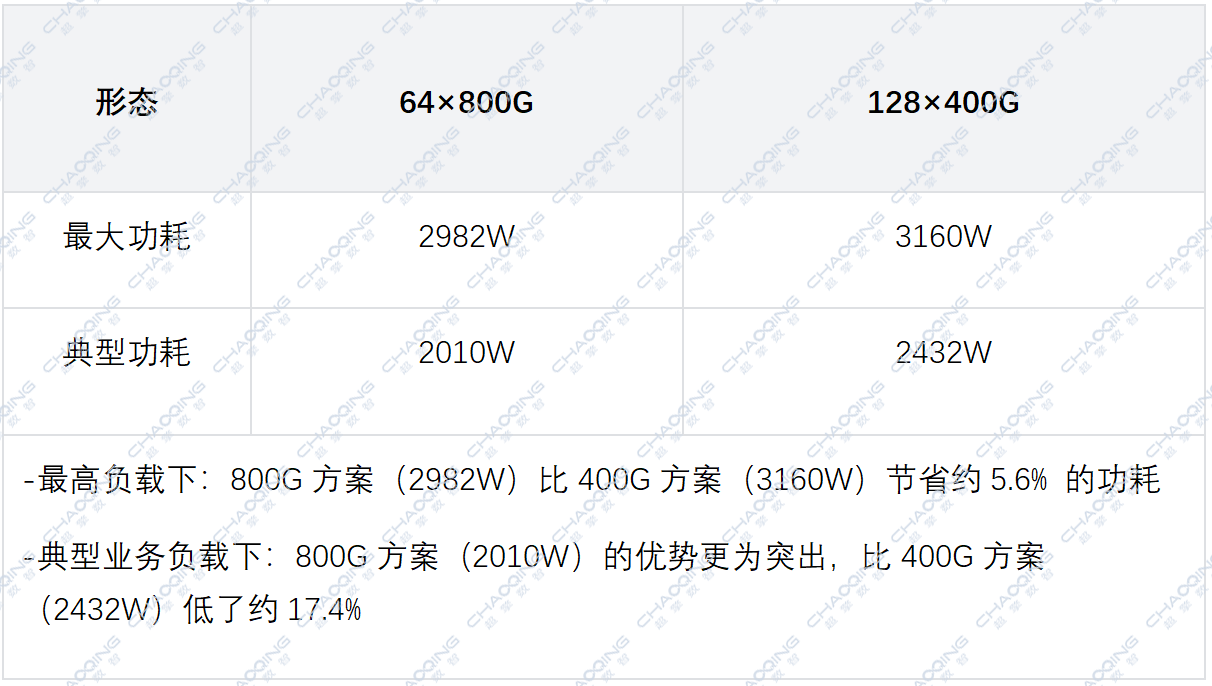
同时更低的整机满载发热量,能够有效降低机房空调制冷压力,减少制冷系统能耗损耗,助力AIDC机房维持更优PUE指标;单设备功耗更低也降低了单机柜配电负荷,可在标准机柜供电配额内实现更多网络设备高密度部署,充分释放机柜供电与散热资源潜力。在AI集群全年7×24小时不间断运行场景下,64×800G低功耗、低发热、散热压力小的特性,不仅延缓硬件老化、提升设备运行稳定性,更能持续缩减电费与制冷运维开支,长期OPEX能耗成本优势十分突出。
单路径高带宽性能与低时延表现。分布式AI训练(尤其是万亿参数大模型的全简约、集体通信)不仅对时延有严格要求,更对单流带宽承载能力有极高需求 ——大模型参数同步、梯度交换需要超大单流带宽支撑,单流带宽不足会导致数据传输卡顿,直接影响训练收敛效率。64×800G配置中,800G单链路作为高带宽传输通道,无需依赖ECMP多路径聚合,可实现单路径高带宽无阻塞转发,减少多路径路由协商、流量拆分与重组的开销,大幅降低端到端转发时延与时延抖动。而800G单链路可直接承载大模型训练的超大单流流量,避免多路径转发的时延波动,同时减少路径切换带来的拥塞风险,尤其适配超大规模AI集群的分布式训练场景,提升训练任务的稳定性与收敛效率。
四、两种形态如何选择:
没有绝对优劣,只有场景适配
从技术特性和部署经验来看,128×400G与64×800G并不存在绝对优劣。
更合理的选型方式,是围绕业务场景、建设阶段、网络基础、成本预算和未来演进路径进行综合判断。

如果企业更关注平滑升级、细粒度扩展、现有400G生态兼容和初期成本控制,128×400G更适合。
如果企业更关注高密度部署、布线简化、长期能耗优化和超大规模AI训练性能,64×800G更具优势。
五、AI网络选型,正在从参数比较走向系统落地
在AI基础设施建设进入深水区后,网络选型不再是简单比较400G与800G,也不是单纯追求更高带宽。真正重要的是:网络架构能否匹配业务负载,能否支撑未来扩展,能否降低长期运维复杂度,能否让GPU算力持续高效运行。
51.2T交换机的64×800G与128×400G两种形态,代表了AI数据中心网络演进中的两条重要路径。一种强调高密度与规模化效率,一种强调细粒度与平滑演进。企业需要根据自身业务阶段和建设目标,选择最适合自己的网络架构。
面向未来,AI集群规模仍将持续扩大,数据中心网络也将继续向更高带宽、更低时延、更强可观测和更高自动化方向发展。在这一趋势下,网络不再只是算力集群的连接层,而是决定AI基础设施效率、稳定性与成本结构的核心底座。
超擎数智将持续依托在“算力、网络、存储”等方面的AI应用全栈方案能力,帮助更多企业构建高性能、高可靠、可持续演进的新一代AI基础设施,让网络真正成为释放AI算力价值的关键引擎。

公众号


电话

需求反馈
