



















咨询服务热线:400-0698-860
邮箱:info@chaoqing-i.com
业务中心 - 上海超擎数智科技有限公司:上海市徐汇区龙启路158号1幢灿星大厦19层1911
业务中心 - 北京超擎数智科技有限公司:北京市海淀区北三环西路99号西海国际中心1号楼907
研发中心 - 武汉超擎数智科技有限公司:武汉东湖高新区金融港二路9号联发科武汉研发中心2楼





在具身智能与机器人技术日新月异的当下,AI研发的重心正从单纯的“数据驱动”向“决策与控制”深度演进。作为实现自主交互的核心技术,强化学习能让智能体在虚拟环境中进行高频次、低成本的试错,已成为具身智能研发的必经之路。
然而,强化学习的工程落地并非易事。它要求计算平台不仅能处理神经网络的训练,还要同时支撑大规模并行仿真环境的运行以及实时的策略推理。
近期,超擎数智技术团队基于 NVIDIA RTX PRO 5000 (72GB) 搭建了全栈强化学习测试平台,并在 NVIDIA Isaac 仿真生态下完成了从环境定义、数据采样、策略训练到可视化推理的全流程验证。
一、具身智能时代,强化学习的核心需求
强化学习:从规则编写到自主学习
在人工智能的发展过程中,强化学习是一类面向“决策与控制”的重要方法。与传统监督学习依赖标注数据不同,强化学习更关注智能体如何在环境中通过连续交互获得经验,并逐步形成能够完成任务的策略。
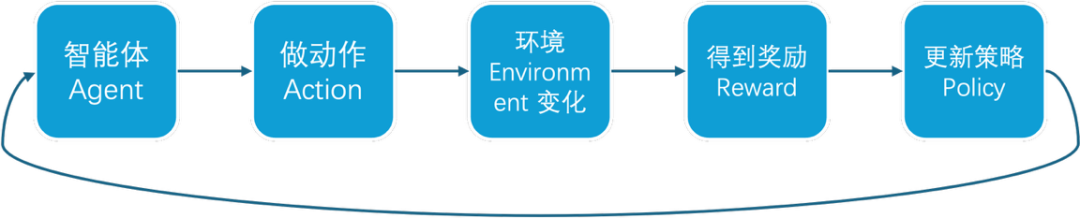
在一个典型的强化学习系统中,智能体会根据当前环境状态选择动作,环境在接收动作后发生变化,并向智能体反馈奖励或惩罚。经过大量交互和策略更新后,智能体会逐渐学习到在不同状态下应该采取何种动作,从而最大化长期收益。
这一过程并不是一次性的线性流程,而是一个持续循环:智能体根据当前状态选择动作,环境反馈新的状态和奖励,智能体再根据这些经验更新策略,并进入下一轮决策。
在机器人和具身智能场景中,强化学习具有很高的应用价值。很多真实任务很难完全依靠人工规则描述,例如移动机器人绕障导航、机械臂抓取不同形状的物体、智能体在动态环境中规划路径等。这些任务往往涉及连续状态、高维动作和复杂物理交互,单纯依靠固定规则很难覆盖所有情况。
因此,更可行的方式是在仿真环境中构建任务,让智能体进行大规模试验和学习,并在训练过程中不断优化策略。相比直接在真实设备上反复试错,仿真训练可以显著降低成本和风险,也便于快速修改场景、奖励函数和任务参数。
面向训练、推理与强化学习仿真的GPU需求
在AI研发和应用验证过程中,GPU承担的任务已经不只是单一的模型训练。对于一套面向AI开发的测试平台来说,它既需要支持模型训练,也需要承担推理验证、可视化测试,以及更复杂的仿真训练任务。
强化学习仿真训练就是一个典型场景。与使用固定数据集的模型训练不同,强化学习需要智能体在仿真环境中不断交互,通过采样、奖励反馈和策略更新逐步学习完成任务。这个过程里,GPU不只是在训练神经网络,还要同时支撑仿真环境运行、交互数据生成,以及每一步的策略推理。
随着并行环境数量增加,训练可以获得更高的采样效率,但对显存容量和持续计算能力的要求也会同步提升。更多环境意味着更多状态数据、更大的采样batch、更高的仿真负载,以及更频繁的策略更新。
RTX PRO 5000 72GB的优势,正体现在这类复合型AI工作负载中。大显存为更多并行环境、PPO采样Batch、观测数据和缓存提供空间;高算力则支撑仿真交互、策略推理和模型更新持续运行。在Isaac Sim / Isaac Lab这类流程中,它可以帮助研发团队完成从仿真、采样、训练到推理验证的完整流程验证。
Isaac Sim与Isaac Lab
Isaac Sim是 NVIDIA 面向机器人仿真和物理AI开发的平台。它基于OpenUSD构建,可以用于搭建机器人、传感器、场景、光照、材质和物理交互环境。对于机器人学习而言,Isaac Sim的作用是提供一个可控、可重复、可扩展的虚拟世界,让研发人员可以在真实设备之外进行训练、验证和调试。
Isaac Lab则是在Isaac Sim之上的机器人学习框架,更偏向训练任务组织和算法接入。它提供了强化学习、模仿学习、运动规划等工作流支持,方便用户定义observation、action、reward、reset、termination 等训练要素,并接入RSL-RL、RL-Games、Stable-Baselines3等算法生态。
简单来说,Isaac Sim更像是“仿真世界和物理引擎”,Isaac Lab更像是“机器人学习任务和训练框架”。两者结合后,可以把机器人策略训练从单纯写算法,扩展成一套完整的仿真、采样、训练、评估和可视化流程。
二、RTX PRO 5000强化学习训练实测
测试环境:Isaac Sim+Isaac Lab+RSL-RL PPO
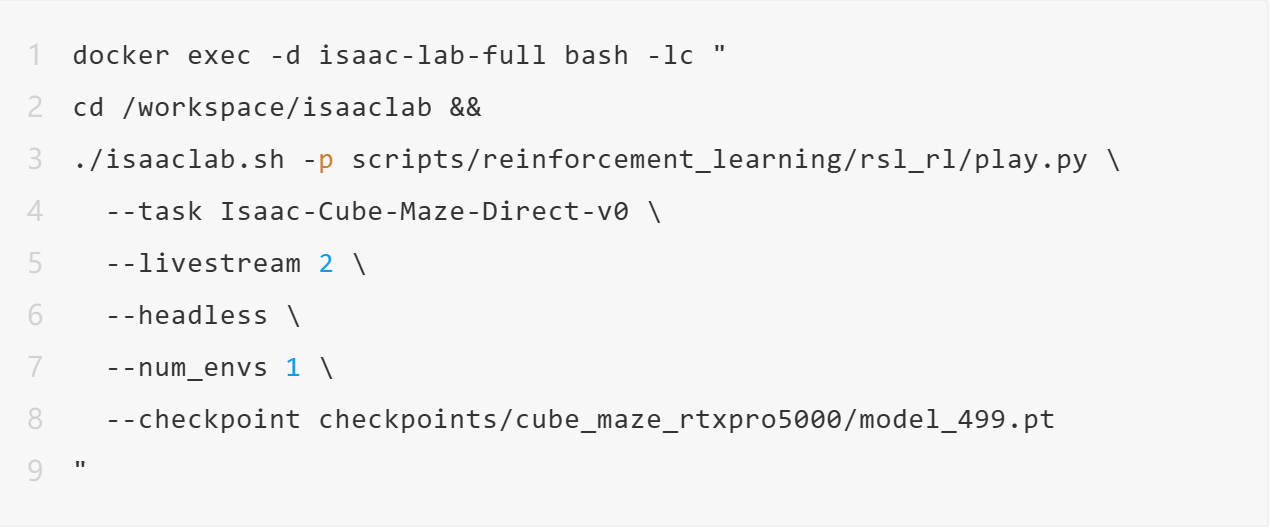
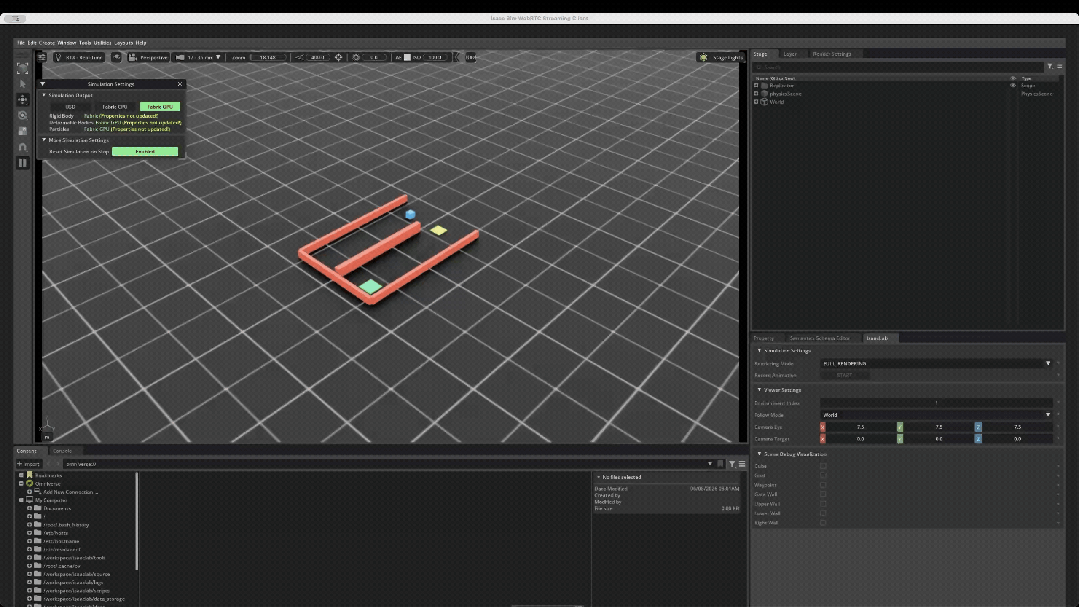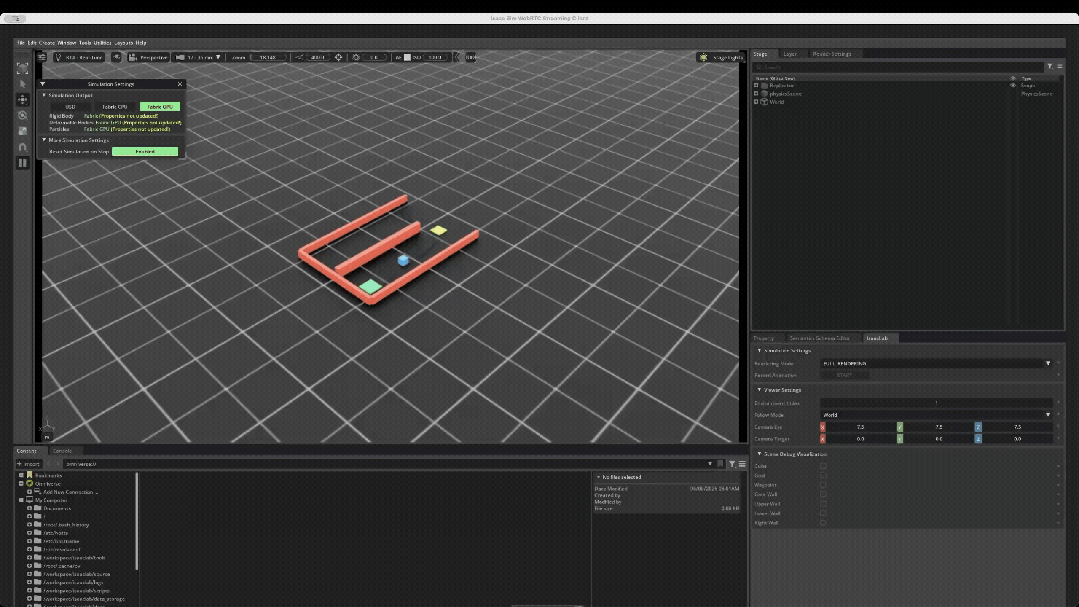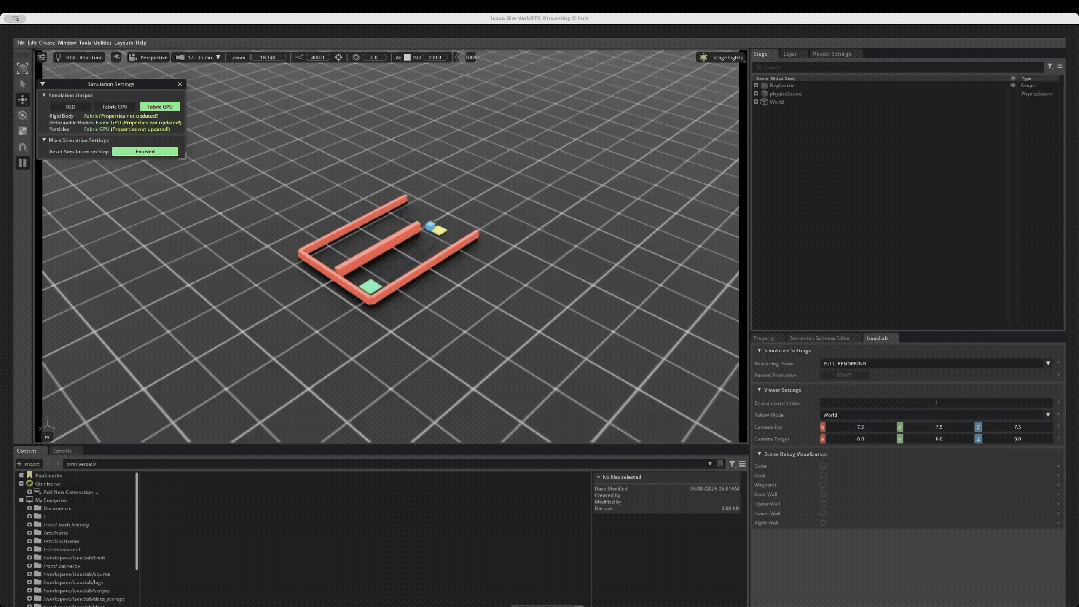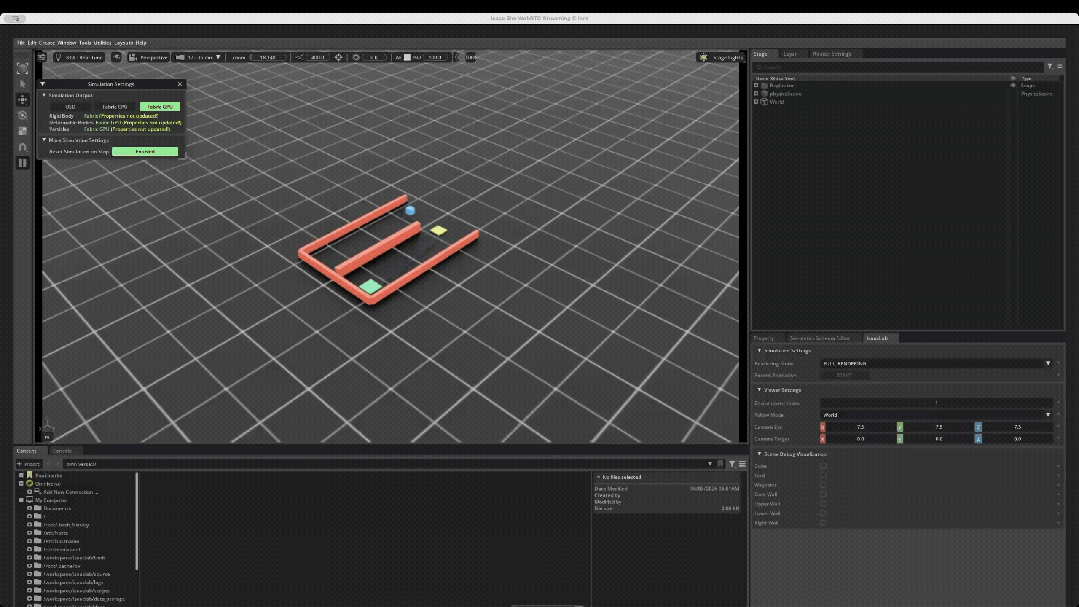
为了验证硬件平台承载完整强化学习闭环的能力,技术团队在Isaac Lab中自主构建了一个具备强可解释性的Cube Maze(方块迷宫绕障)任务。
1. 任务及空间定义
任务目标:控制蓝色方块从起点出发,先移动到黄色中间目标点(Waypoint),随后绕过红色障碍墙体,最终抵达绿色终点(Goal)。
空间配置:动作空间:2(在X、Y方向上施加的控制力)
观测空间:13(包含自身位置、速度、到目标点的相对距离、与墙体的距离等维度)

2. 引导智能体行为的“奖励函数”设计
强化学习的策略收敛极度依赖于奖励机制(Reward Function)的精细度。在本任务中,若只对最终目标给奖,智能体极易在前期迷失。因此,将奖励拆解为前进引导奖励、阶段性奖励以及约束惩罚:

技术策略: Waypoint(中间目标)采用一笔总账式的单次阶段奖励。若持续给奖,智能体往往会选择在中间点附近徘徊停滞,以刷取局部奖励。到达Waypoint后,系统自动切入针对终点的progress_reward,并配合stall_penalty,逼迫智能体快速绕墙向终点推进。
3. PPO配置:放大采样Batch,提高训练吞吐
在RSL-RL PPO配置中,num_steps_per_env决定每个环境在一轮迭代中采样多少步。结合命令行传入的num_envs=4096,单轮采样规模可以达到4096×48=196,608 steps,从而更充分地利用RTX PRO 5000 72GB的并行计算能力。

这类配置的意义在于把更多环境交互数据集中到一次训练迭代中。对于强化学习来说,GPU的价值不仅体现在神经网络更新上,也体现在能否同时承载大量并行环境,让采样、训练和策略更新形成更高效的闭环。
4. 容器化运行流程
为了让训练、推理和可视化复用同一套环境,我们将 Isaac Lab、任务代码、依赖和运行脚本统一放进 Docker 容器。这样既减少了环境配置的不确定性,也方便后续在不同测试环境中复现和调整。
训练命令如下:

训练完成后,可以加载checkpoint启动可视化推理,用1个环境观察策略是否真正学会绕过障碍并到达目标。
三、实测数据表现
在单卡RTX PRO 5000 (72GB) 环境下,运行驱动版本为580.126.09,在500轮的密集迭代中,累计总采样规模达到了98,304,000 steps。
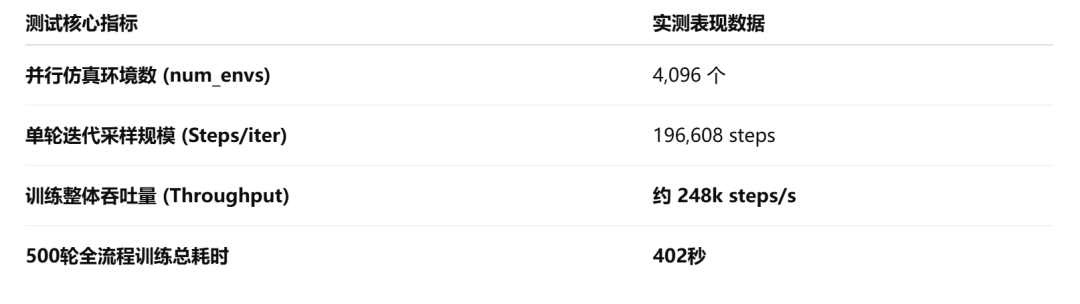
实测数据显示,在RTX PRO 5000 72GB单卡环境下,系统能够稳定运行4096个并行仿真环境实例,并完成交互采样与状态更新。训练过程中平均吞吐约为248k steps/s,接近一亿步的大规模强化学习采样可以在数分钟内完成。测试过程中未观察到显存不足导致的训练中断或明显性能退化,仿真、采样、PPO策略更新与可视化推理构成了完整的强化学习验证闭环。
从这套流程可以看到,强化学习训练并不是单独依赖某一个硬件或软件组件,而是一套从底层算力到上层任务框架的系统工程。RTX PRO 5000 72GB提供大显存和高算力,支撑并行仿真、策略训练和可视化推理;CUDA、GPU驱动和PyTorch生态提供训练与推理加速基础;Isaac Sim提供机器人仿真、场景构建和可视化能力;Isaac Lab则把观测、动作、奖励函数、并行环境和强化学习算法接口组织成可复用的训练流程。
四、超擎数智:以全栈实力交付可持续演进的强化学习能力
本次强化学习测试表明,面向具身智能和机器人学习的AI基础设施,并不只是“有没有GPU”的问题。真正影响训练效率和验证效果的,是硬件平台、GPU驱动、CUDA、PyTorch、容器环境、Isaac Sim / Isaac Lab、强化学习算法、任务建模和奖励函数设计之间的协同。任何一个环节的脱节,都可能导致显存溢出、采样停滞或训练不收敛等工程化难题。
这也意味着,对于希望开展强化学习、物理仿真、机器人控制和具身智能探索的团队来说,真正需要的是一套可运行、可验证、可迭代的AI全栈方案。作为AI原生的基础设施整体解决方案提供商,这也是超擎数智的核心价值:不只交付硬件设备,而是提供从硬件选型、软硬件栈部署、任务适配、性能调优到持续运维的全流程一站式技术支持。
随着AI应用从模型训练走向真实业务和物理世界验证,企业对算力平台的要求也在发生变化:不仅要关注硬件参数,更要关注系统能否稳定运行、流程能否复现、结果能否验证、后续能否持续扩展。超擎数智的技术团队能够深度介入业务前端,协助研发企业跨越复杂的软硬件工程鸿沟,构建稳定、高效、可持续演进的算力基础设施,让具身智能的强化学习与物理仿真真正转化为触手可及的生产力。

公众号


电话

需求反馈
