



















咨询服务热线:400-0698-860
邮箱:info@chaoqing-i.com
业务中心 - 上海超擎数智科技有限公司:上海市徐汇区龙启路158号1幢灿星大厦19层1911
业务中心 - 北京超擎数智科技有限公司:北京市海淀区北三环西路99号西海国际中心1号楼907
研发中心 - 武汉超擎数智科技有限公司:武汉东湖高新区金融港二路9号联发科武汉研发中心2楼





随着大模型发展全面迈入规模化推理部署的新阶段,推理性能、成本控制与资源利用率,正在成为智算基础设施建设的核心命题。在这一过程中,存储已不再只是数据承载的底层资源,而是影响GPU利用率、推理延迟与系统吞吐的关键变量。
ODCC AI存储实验室作为面向AI基础设施前沿技术验证的重要平台,依托超擎数智高性能算网环境与全栈技术服务能力,聚焦先进存算分离架构,持续开展面向AI训练、推理、存储部件与系统协同的实证测试,为行业关键技术选型与系统优化提供可量化、可复用的参考依据。
继ODCC AI存储实验室发布焱融YRCache推理存储系统KV Cache评测成果后,本次将进一步聚焦测试中的核心存储硬件英韧科技洞庭-N3X,一款面向AI场景打造的企业级 SSD 产品。在KV Cache从GPU显存向外部存储卸载的过程中,高性能SSD正从传统意义上的“存储介质”,跃升为影响推理流水线效率的重要引擎。
当大模型上下文窗口持续向百万级演进,KV Cache规模急剧膨胀,GPU的HBM容量不足已成为高并发、长上下文推理场景下的典型瓶颈。此时,外部存储系统是否能够以足够低的延迟、足够高的带宽和足够稳定的IOPS响应KV Cache读写请求,直接影响首Token延迟、单Token输出时间以及GPU整体利用率。
在本次ODCC AI存储实验室的KV Cache专项测试中,英韧洞庭-N3X凭借卓越的单盘性能,为存储系统实现推理提速、长上下文支撑与成本优化提供了坚实的硬件底座。
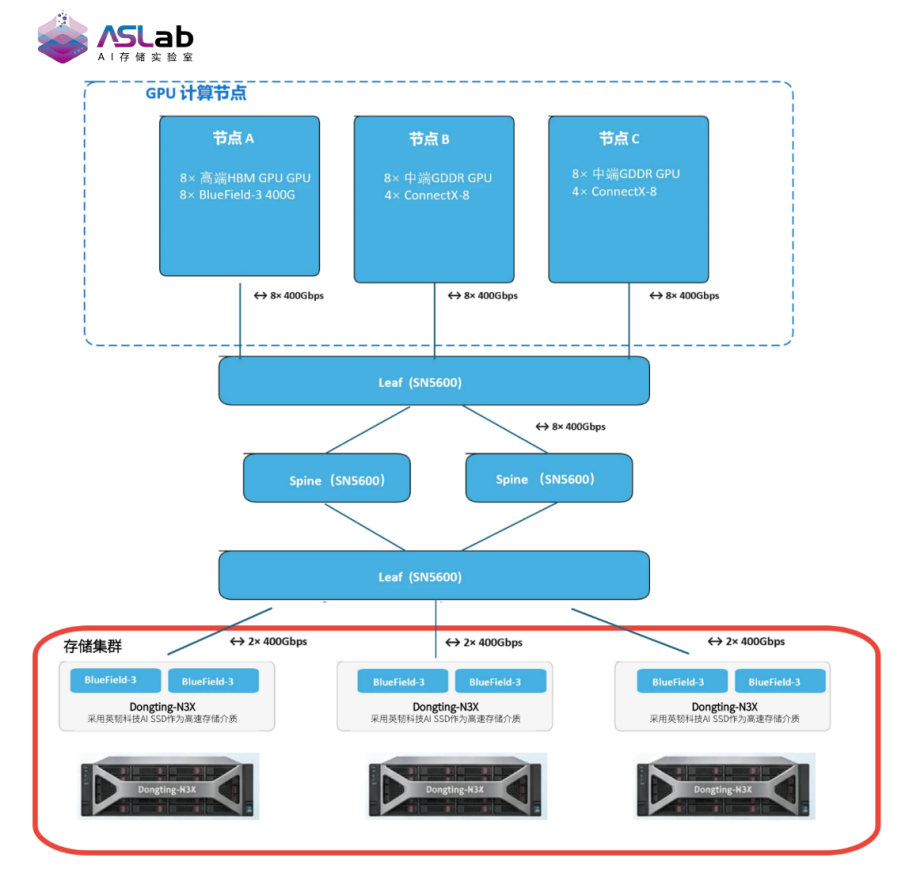
1、构建KV Cache全栈验证环境
本次专项测试,超擎数智在ODCC AI存储实验室中提供了贴近真实智算中心部署场景的基础设施环境,包括高性能GPU服务器、分布式存储集群、高速网络拓扑以及面向大模型推理任务的系统测试平台。通过这一环境,实验室能够从“部件—系统—应用”多个维度,对AI推理存储方案进行端到端评估。
本次,英韧科技洞庭-N3X承担了存储集群的核心硬件支撑任务。作为面向AI场景打造的企业级SSD产品,洞庭-N3X采用PCIe Gen5接口与优化的数据引擎,围绕高带宽、低延迟、高并发、稳态输出等关键能力进行设计,目标直指大模型训练与推理过程中的“内存墙”问题。
在KV Cache卸载场景中,SSD不再只是冷数据的仓库,而是持续参与推理数据流转的高频访问介质。其性能水平将直接决定GPU能否持续获得数据供给,进而影响整个推理系统是否能够保持高吞吐、低延迟运行。
2、单盘性能硬核突破,为KV Cache高效流转提供物理基础
KV Cache读写具有典型的高并发、高随机、小I/O访问特征,同时在缓存预加载、批量迁移、长上下文处理等场景下,也对顺序带宽提出了极高要求。ODCC AI存储实验室测试结果显示,英韧洞庭-N3X在顺序带宽、随机IOPS以及稳态输出能力上均展现出突出的单盘性能优势。
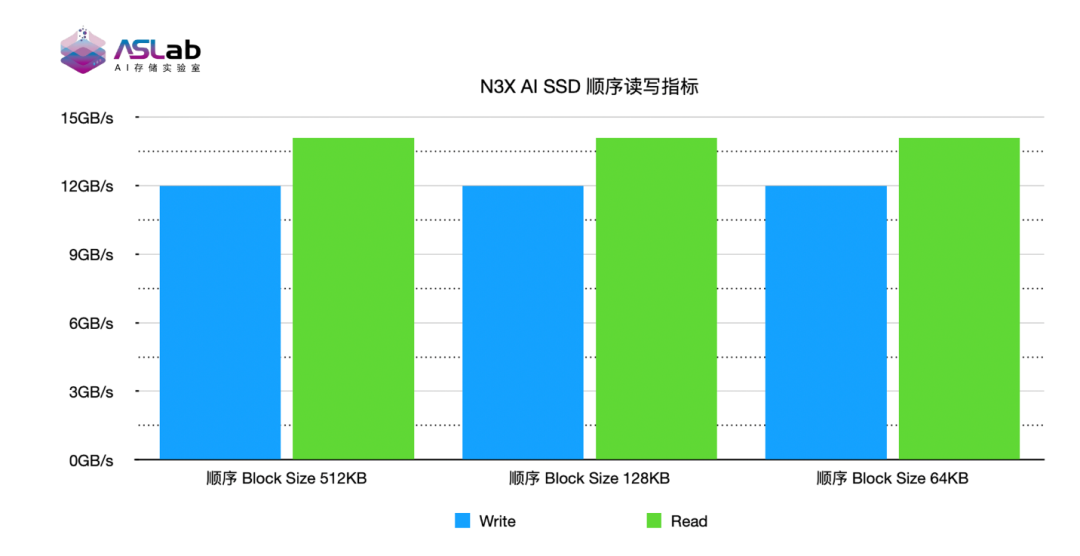
14GB/s顺序带宽 支撑存储系统高效数据迁移
在需要预加载KV Cache或进行批量缓存数据迁移的场景中,顺序带宽直接决定数据搬运效率。测试显示,英韧洞庭-N3X顺序读速度达到14GB/s,顺序写速度逼近12GB/s,充分释放PCIe Gen5接口的传输潜力。
对于AI推理系统而言,这意味着在大规模长上下文任务启动、缓存批量加载或跨节点数据迁移过程中,底层SSD能够为上层存储系统提供更高效的数据供给能力,减少数据准备时间,提升整体推理链路的响应效率。
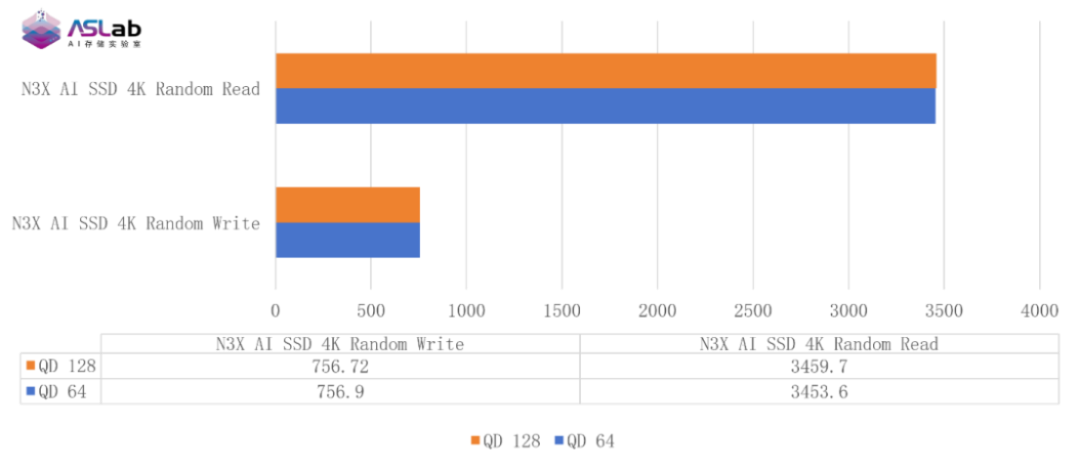
稳态随机读写超千万IOPS 让存储系统持久输出
KV Cache在推理阶段的访问模式并非单纯的大块顺序读写,而是大量并发随机小I/O请求。尤其在多用户并发、长上下文复用、缓存命中与卸载回读场景中,SSD的随机读写性能与稳态表现尤为关键。
在基准测试中,英韧洞庭-N3X的4KB随机读性能接近3500K IOPS,4KB随机写性能达到756.72K IOPS,均高于标称性能。凭借全盘稳态下的持续IOPS输出能力,搭载N3X的存储系统在整个评测过程中保持稳定运行,能够持续高效响应KV Cache读写请求。
这也进一步说明,在AI推理存储架构中,企业级SSD的价值不仅体现在峰值性能,更体现在长时间高负载运行下的稳定输出能力。对于真实智算中心而言,这一能力直接关系到系统服务质量与推理任务的稳定性。
3、从单盘到系统:高性能SSD放大KV Cache卸载收益
ODCC AI存储实验室KV Cache专项测试并未停留在单盘基准层面,而是进一步将英韧洞庭-N3X纳入真实推理系统链路,与推理存储系统、高速网络和GPU服务器进行联合验证。
测试结果显示,N3X的单盘性能优势能够有效转化为系统级收益,在延迟、吞吐、GPU利用率与成本结构等方面形成显著提升。
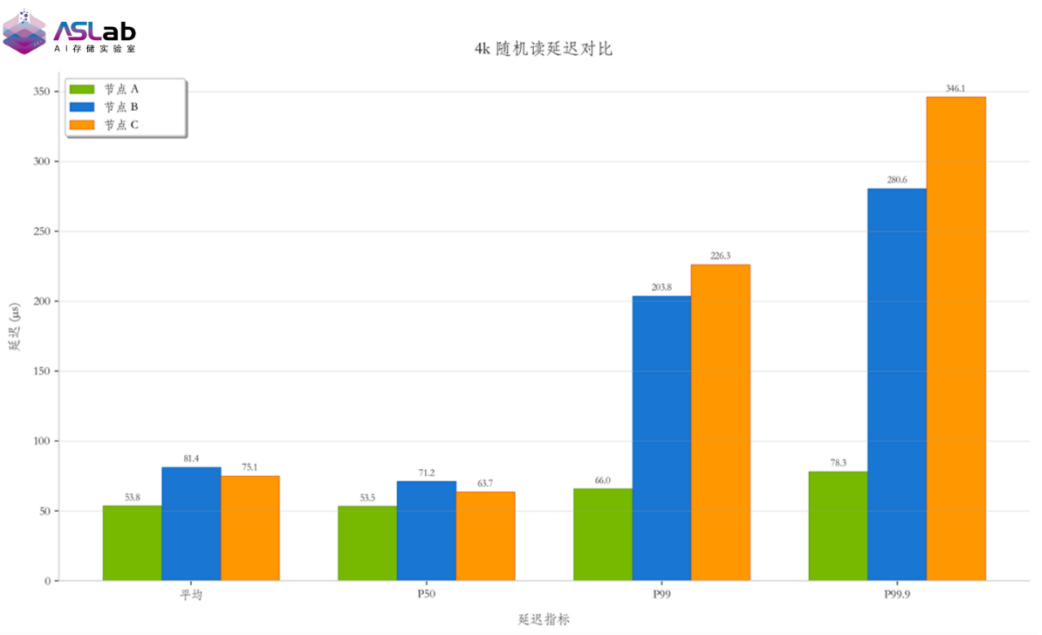
微秒级尾延迟,为存储系统提供“零等待”基础
在大模型推理过程中,Decode阶段需要持续访问与更新KV Cache。此时,存储路径的尾延迟将直接影响Token生成的连续性与稳定性。
本次测试显示,在采用高端GPU的服务器节点上,英韧洞庭-N3X实现了低至66μs的P99延迟,写入延迟稳定控制在微秒级。得益于这一低延迟能力,搭载N3X的存储系统在KV Cache卸载场景中能够实现近乎“零感知”的数据写入与读取支撑,使GPU在执行推理任务时尽可能减少因数据等待造成的空转。
对于上层应用而言,这意味着长文本生成、多轮对话、代码生成、文档分析等场景能够获得更流畅的生成体验;对于智算中心而言,则意味着GPU资源能够被更充分利用,单位算力投入产出比进一步提升。
吞吐量显著提升,中端GPU推理效能接近高端
在长上下文和高并发任务中,GPU显存容量往往成为限制吞吐提升的关键因素。当KV Cache能够通过高性能存储系统实现高效卸载后,GPU显存压力得到释放,推理并发能力与吞吐表现随之显著提升。
测试结果显示,在输入长度大于等于10K Token的场景下,基于英韧洞庭-N3X的存储系统使首Token延迟从秒级降至毫秒级;在特定缓存命中场景下,加速比可达百倍。吞吐量方面,中端GPU服务器提升约20倍,高端GPU服务器提升约12倍。
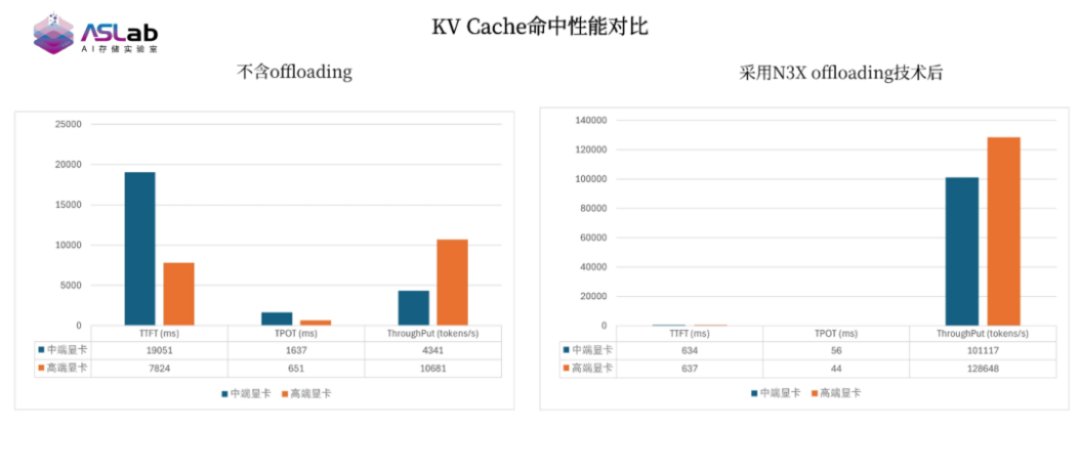
这一结果具有重要产业价值。它表明,通过高性能SSD与推理存储系统的协同优化,高性价比的中端GPU也能够在部分长上下文推理场景中展现出接近高端GPU的系统级效能。
对于正在建设或扩容智算中心的企业而言,这为基础设施选型提供了新的思路:推理性能的提升不再只能依赖单向堆叠高端GPU,也可以通过“以存强算”的系统架构创新,释放中端算力资源潜能,从而实现更优的成本结构。
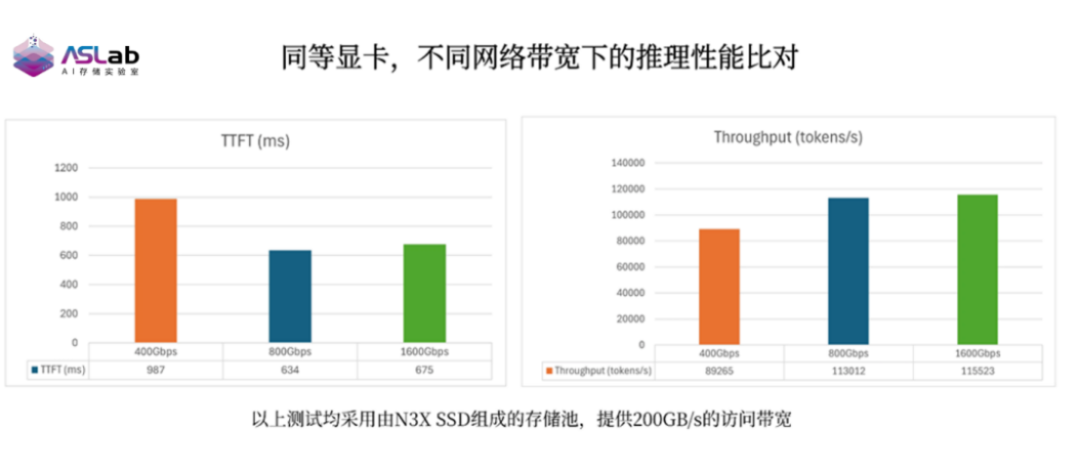
存储与网络协同,高速算网进一步放大卸载收益
本次测试还围绕不同网络带宽环境下的KV Cache卸载效果进行了对比分析。结果显示,在存储池能够满足网络带宽需求的前提下,网络带宽越高,推理吞吐量提升越显著。
针对中端GPU服务器,当网络从400G进一步提升至800G乃至1.6T时,KV Cache卸载的加速效果呈增长态势。高速网络与英韧洞庭-N3X的高读写性能形成协同,使PD阶段的数据流转效率持续提升,进一步减少数据搬运对GPU推理任务的影响。
针对终端GPU服务器,当网络从400G进一步提升至800G乃至1.6T时,KV Cache卸载的加速效果呈增长态势。
4、软硬协同验证路径,推动AI存储从部件走向系统标准
本次ODCC AI存储实验室KV Cache测试,联合焱融YRCache推理存储系统与英韧洞庭-N3X企业级SSD,实现了从存储软件到硬件底层的深度协同验证。
从测试结果来看,YRCache通过多级KV缓存架构,有效调度GPU显存、主机内存、本地NVMe SSD以及分布式文件存储,突破单一显存容量边界;英韧洞庭-N3X则以高带宽、低延迟、高IOPS与稳态输出能力,为KV Cache卸载提供坚实的硬件基础。二者协同,使存储系统真正进入AI推理主路径,成为释放算力、降低成本、提升并发的关键支点。
更重要的是,本次测试再次体现了超擎数智在ODCC AI存储实验室中测试环境与测试服务的专业。依托超擎数智在“存储-算力-网络”方面的综合能力,能围绕AI基础设施中的关键瓶颈问题,组织产业链上下游开展真实环境下的联合验证。
5、以存强算,超擎数智携手生态伙伴共建AI基础设施新范式
随着大模型推理规模持续扩大,KV Cache的存储与管理正在成为AI基础设施架构演进中的核心议题。超擎数智将持续发挥高性能算网环境与全栈技术服务能力,围绕KV Cache、AI存储系统、企业级SSD、高速网络、GPU集群等关键方向,推进“部件—系统—应用”的全链路协同测试。
本次英韧洞庭-N3X的测试结果表明,高性能SSD正在成为AI推理时代不可或缺的关键支撑。未来,ODCC AI存储实验室将继续携手更多产业生态伙伴,以系统化测试、标准化评估和实证化数据,助力AI存储技术加速成熟,推动智算基础设施从“以算为中心”走向“存算协同、以存强算”的新阶段。

公众号


电话

需求反馈
