



















咨询服务热线:400-0698-860
邮箱:info@chaoqing-i.com
业务中心 - 上海超擎数智科技有限公司:上海市徐汇区龙启路158号1幢灿星大厦19层1911
业务中心 - 北京超擎数智科技有限公司:北京市海淀区北三环西路99号西海国际中心1号楼907
研发中心 - 武汉超擎数智科技有限公司:武汉东湖高新区金融港二路9号联发科武汉研发中心2楼





大模型进入“长跑”时代,算力瓶颈正在悄然转移。从8K到128K,再到如今百万级的Token上下文,大模型的“记忆力”正在经历爆发式增长。对于企业而言,这意味着AI真正成为了处理海量金融研报、审核超长法律合同、甚至分析整个代码库的生产力工具。
但“长记忆”是有代价的。
在Transformer架构下,为了保证推理速度,系统必须将历史Token的注意力键值(Key-Value Cache,简称KV Cache)常驻在GPU显存中。当上下文长度突破10万(100K)量级时,KV Cache的数据量会呈线性爆炸。
这就导致了一个尴尬的局面:GPU的计算能力尚未被充分利用,显存却已经率先成为瓶颈。
面对这一挑战,业界提出了两种主流优化思路:
一是通过PD分离(Prefill-Decode Disaggregation)将计算密集的Prefill阶段和访存密集的Decode阶段解耦,避免资源争抢;
二是通过KVCache Offload将缓存数据迁移到外部存储,为显存“减负”。这两种技术相辅相成,共同构成了长上下文推理的基石。
但KVCache Offload能否发挥最大效用,关键取决于连接GPU与存储的那条“高速公路”——网络带宽。
是继续堆GPU来换取显存空间?还是寻求一种更聪明的架构变更?
在ODCC牵头下,超擎数智联合 NVIDIA 、焱融科技、英韧科技、DaoCloud、纳多德,在自有的高性能计算和人工智能研发测试中心,投入数千万设备,进行了一场跨厂商的深度验证。评估 NVIDIA Spectrum-X 高速网络环境下,KV Cache卸载带来的性能收益,同时分析东西向和南北向高带宽网络对AI推理性能的影响。
核心思路:KV Cache Offload,给GPU显存“减负”
面对显存危机,解决思路是明确的:在长上下文大规模推理场景下,会产生大量的缓存数据,既然显存装不下,那就把KV Cache搬出去。
这就是KV Cache Offload技术——将缓存数据迁移到GPU外部的存储介质中,需要时再取回。
在PD分离架构中,这一技术尤为重要:Prefill节点产生的海量KVCache可以迅速卸载到共享存储池,而Decode节点则能以极低延迟拉取所需缓存,从而实现真正的计算与访存分离。
但这带来了一个巨大的技术挑战:速度。
如果外部传输速度跟不上GPU的计算速度,推理就会卡顿,用户体验会大打折扣。因此,这项技术的成败,并不取决于存储介质本身,而取决于连接GPU与存储的那条“高速公路”——网络带宽。
为了验证这一架构在极端场景下的真实表现,超擎数智构建了一套顶级的测试环境:
平台层:采用Dao Cloud Enterprise 5.0 (DCE 5.0)。
模型负载:实测DeepSeek-R1(671B)和Qwen3(235B)等主流大模型,上下文长度分别拉满至128K、40K。
计算层:覆盖了高端(NVIDIA H20)与中端(NVIDIA RTX Pro 6000D)两类典型推理平台。
网络层:部署了基于 NVIDIA Spectrum-X 的以太网架构,提供从400G到1.6T的超宽带“高速公路”东西向网络。
存储层:采用焱融YRCache高性能推理存储系统、英韧洞庭N3X SSD,专为缓存命中优化。

实测深度解读:高带宽网络如何重塑推理性能?
在近乎严苛的测试中,我们通过两组核心场景验证了高带宽网络对KV Cache卸载架构的决定性影响。
PD一体测试场景
在传统的PD一体架构中,GPU需要同时处理计算和显存内外的数据交换。当KV Cache被卸载到外部存储后,网络的吞吐能力直接决定了Prefill阶段回传历史缓存的效率,进而影响首字延迟(TTFT)这一核心体验指标。
1、带宽即算力:1.6T网络带来的性能飞跃
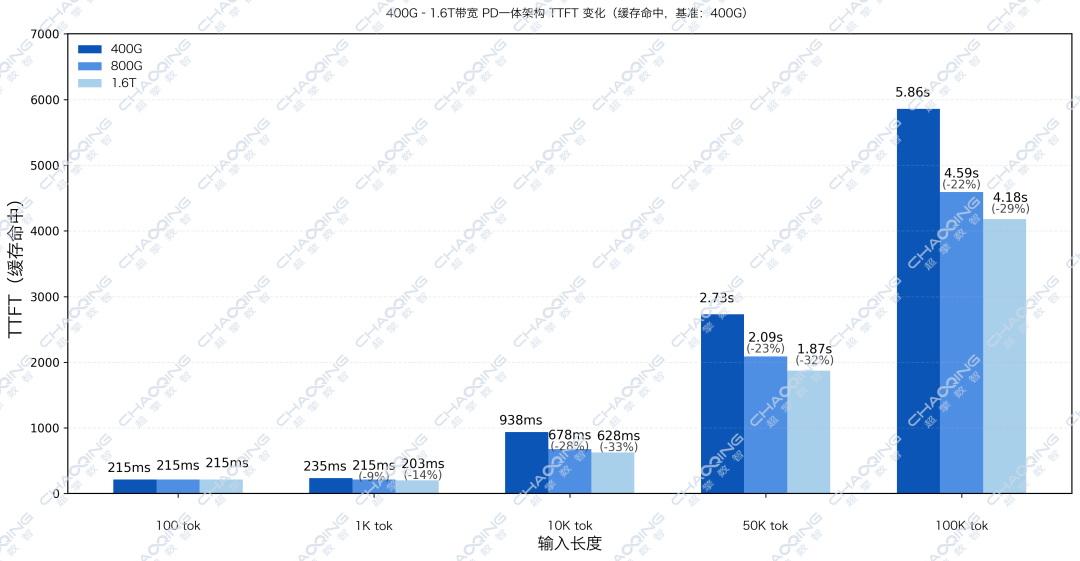
超擎数智技术团队在H20平台运行DeepSeek-R1(671B)模型,模拟100至100K Token的超长文本推理。通过对比不同东西向和南北向带宽下的TTFT,发现带宽升级带来的收益随上下文长度增加而显著放大。
当东西向的带宽,从基准的400G提升至1.6T时,100K场景下的TTFT降低了29%。
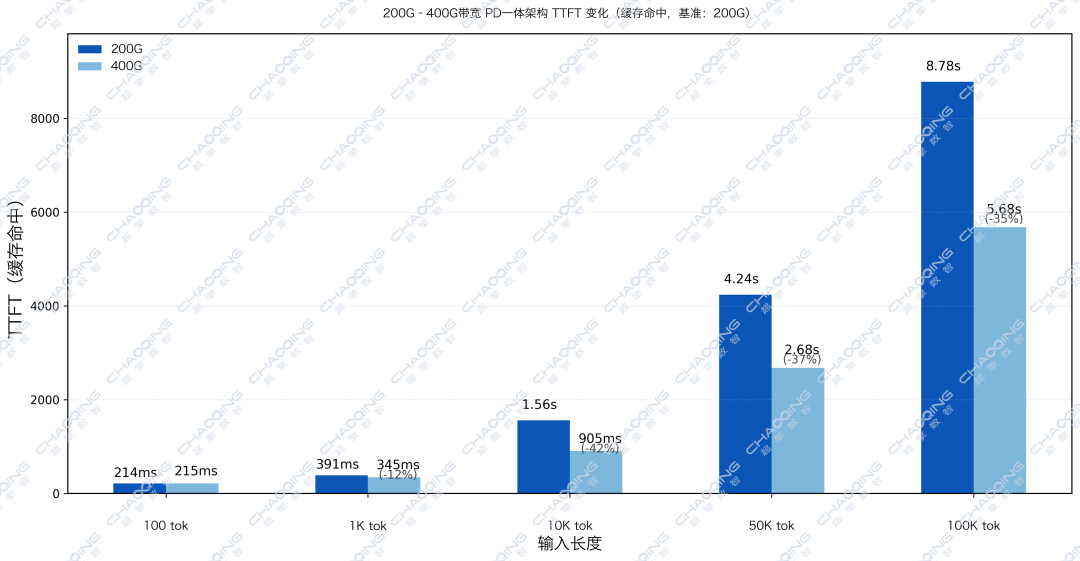
值得一提的是,为了覆盖更多使用场景,本次测试中南北向网络同样承载了GPU-存储的流量。将其带宽从200G升级至400G后,延迟大幅降低了35%。
本组数据印证了KV Cache Offload的核心逻辑:当缓存需要频繁跨网络迁移时,网络带宽成为影响端到端推理吞吐能力的关键因素。在PD一体架构中,这意味着每提升一档带宽,首字延迟就显著降低,网络已成为长文本推理的‘命门’。
2、颠覆性发现:高带宽能“拉平” GPU 的性能差异
通常,中端GPU(如RTX Pro 6000D)在性能上无法与高端GPU(如H20)相提并论。在短文本(100 Tokens)测试中也证实了这一点:由于计算能力的物理差距,H20的速度是RTX 6000D的8.6倍。
但在超长文本(40K Tokens)场景下,当配置了1.6T的超高速网络进行KV Cache卸载时,两者的性能差距被惊人地缩小到了1.3倍左右。
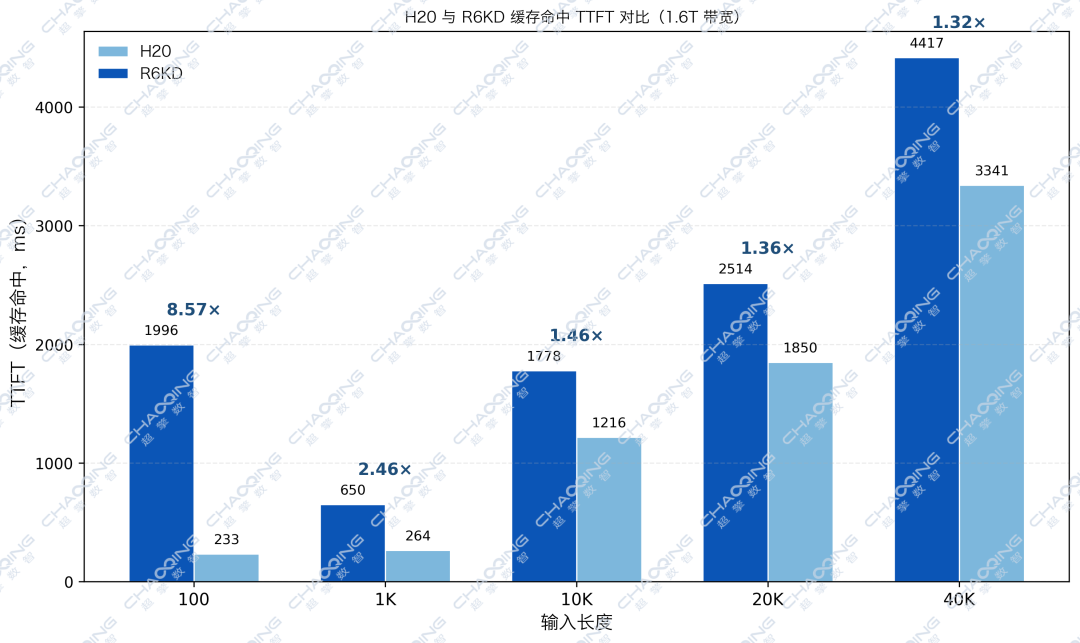
这印证了长文本场景下瓶颈已从计算(Compute Bound)”转移到了“访存与传输(IO Bound)”。此时,谁的网速快、谁的数据吞吐能力强,谁就能占据优势。
PD分离测试场景
PD分离架构本身就是针对PD一体痛点的一次重要优化,但即便“基础分”更高,提升网络带宽依然能带来明确的性能增益。
我们在PD分离测试中,使用RTX Pro 6000D作为Prefill节点、H20作为Decode节点,基于Qwen3(235B)模型进行长文本测试。
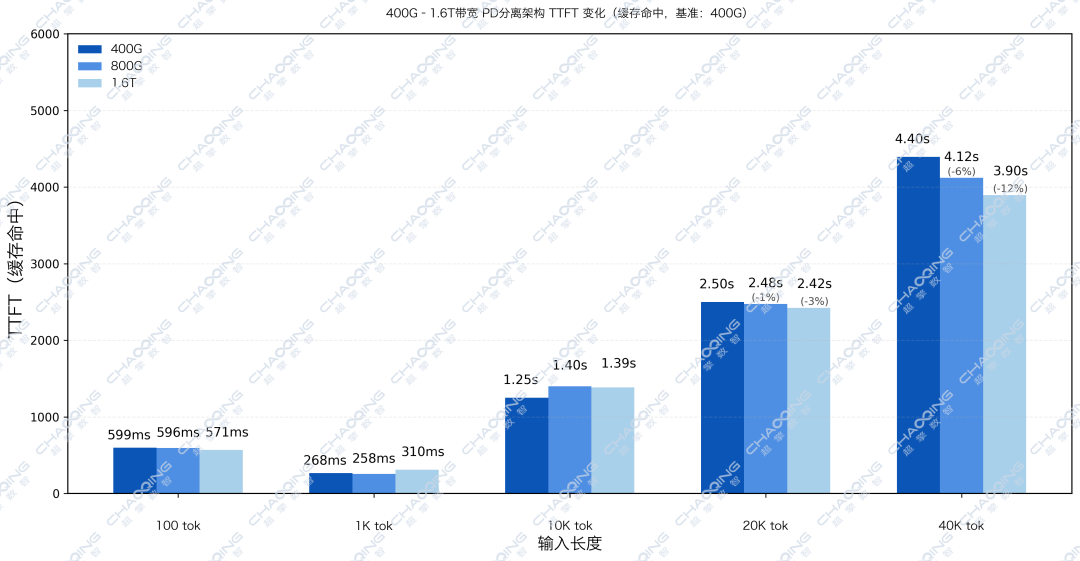
数据显示,在40K Token长文本下,1.6T带宽相比400G降低了12%的延迟。当架构本身已较优时,进一步提升的难度自然加大。
然而,12%的优化不仅意味着用户体验的显著改善,更重要的是,随着Prefill节点算力增强或流水线深度优化,网络在未来很可能再次成为制约因素,届时这12%的优势将转化为更大的性能空间。
通过两组实测对比,我们得出一个清晰结论:网络带宽在推理架构中的价值,随着架构本身的演进呈现出“阶梯式释放”。在PD一体架构中,它是亟待释放的核心瓶颈;在PD分离架构中,它是在已有优化基础上继续突破的关键抓手。无论哪种场景,Spectrum-X 提供的高带宽环境都能为长上下文推理带来切实的性能提升。
为什么超擎数智:能做这样的系统级验证?
本次测试不是一次简单的“跑分”,而是涉及算力、网络、存储、算法的全栈系统工程。之所以能得出如此深刻的架构级结论,源于超擎数智深厚的技术沉淀与基础设施实力。作为 NVIDIA Compute(GPU)和 Networking(网络)的双Elite精英级合作伙伴,超擎数智不仅拥有硬件资源的优势,更具备深厚的技术积淀:
自有高端实验环境:超擎数智自有高性能计算和人工智能研发测试中心,拥有从H20到Spectrum-X网络的全套真实环境,能够先于客户验证最前沿的架构。
全栈技术整合能力:从底层的DPU/DOCA开发,到上层的AI软件栈优化,超擎数智具备将跨品牌厂商的产品整合为一套完整解决方案的能力。
场景化落地经验:超擎数智不仅提供产品,更提供通过验证的“架构服务”。无论客户是需要极致性能的核心系统,还是追求性价比的推理集群,都有现成的数据支撑。
当大模型推理走向深水区,基础设施的建设逻辑正在发生根本性变化。
在PD分离时代,KVCache Offload不再是纸上谈兵,而是可以通过高带宽网络真正落地的实用技术。未来的AI数据中心,网络不只是连接线,而是算力的放大器;存储不只是仓库,而是显存的延伸。算力架构的竞争,也将从单点硬件性能,升级为全栈协同效率的竞争。
随着金融分析、智能制造、生命科学、自动驾驶、政务治理等领域对长文本理解与复杂推理能力的需求持续增长,AI基础设施正在成为新一代产业升级的底层引擎。谁能率先构建高带宽、强协同、可扩展的智能算力体系,谁就能在大模型时代掌握真正的生产力主动权。
超擎数智将持续深耕AI原生基础设施创新,推动网络、存储与算力的深度融合演进,加速形成面向未来的高效能智能底座。以系统级能力为支点,让先进算力真正转化为产业价值,让AI能力深入千行百业,成为数字经济高质量发展的核心驱动力。

公众号


电话

需求反馈
