



















咨询服务热线:400-0698-860
邮箱:info@chaoqing-i.com
业务中心 - 上海超擎数智科技有限公司:上海市徐汇区龙启路158号1幢灿星大厦19层1911
业务中心 - 北京超擎数智科技有限公司:北京市海淀区北三环西路99号西海国际中心1号楼907
研发中心 - 武汉超擎数智科技有限公司:武汉东湖高新区金融港二路9号联发科武汉研发中心2楼





解耦Prefill与Decode,性能提升的边界在哪里?
联合实测揭示:硬件精准分工,可获数倍吞吐跃升;而释放架构全部潜力的关键,在于系统级的协同优化。
为全面验证高性能网络与PD分离、KV Cache Offload这两项技术的性能优势与应用价值,超擎数智联合 NVIDIA 、超云、DaoCloud、纳多德,投入总计数千万元设备与资源,在超擎数智高性能计算和人工智能研发测试中心开展了跨厂商协作测试。
在上篇与中篇,我们已明确技术路线图:将PD分离与KV Cache Offload深度协同,作为提升大模型推理效率的关键路径,并进一步验证了高性能网络对于实现高效Offload的决定性作用。
本期内容,超擎数智将聚焦PD分离架构的全面性能实证,在多个长度上下文(100-50K Tokens)场景下,完成从实验设计、环境搭建、执行测试到不同场景下的实验结果分析。旨在回答一个核心问题:相较于传统PD一体化推理结构,PD分离究竟能带来多少可量化的性能收益?其系统瓶颈又隐藏在何处?
01 测试概述:严谨设计,量化对比
为确保测试结果的可复现性,我们构建了以下测试框架:
任务调度与流量编排
采用基于Proxy的串行化请求调度架构。Proxy充当全局流量控制器,负责维护推理请求的生命周期:
计算节点执行逻辑
存储后端优化与一致性保障
02测试环境:全栈高性能基础设施
本次测试继续依托由超擎数智、NVIDIA、超云、DaoCloud、纳多德共建的顶级实验环境,确保每个环节无性能瓶颈。
硬件环境:
超擎元景H20高性能GPU服务器(1台)
超擎擎天R6KD高性能GPU服务器(1台)
超云CS13000高性能分布式存储(1套)
NVIDIA Spectrum-X 网络架构
软件环境:
操作系统:Ubuntu 22.04.5 LTS
内核版本:5.15.0-161-generic x86_64 GNU/Linux
CUDA 版本:12.8
vLLM版本:0.11.0
LMCache版本:0.3.9post2
LLM模型:/ Qwen3-30B-A3B-Instruct-2507
DaoCloud Enterprise5.0(DCE 5.0)集群调度管理平台
03测试环境拓扑
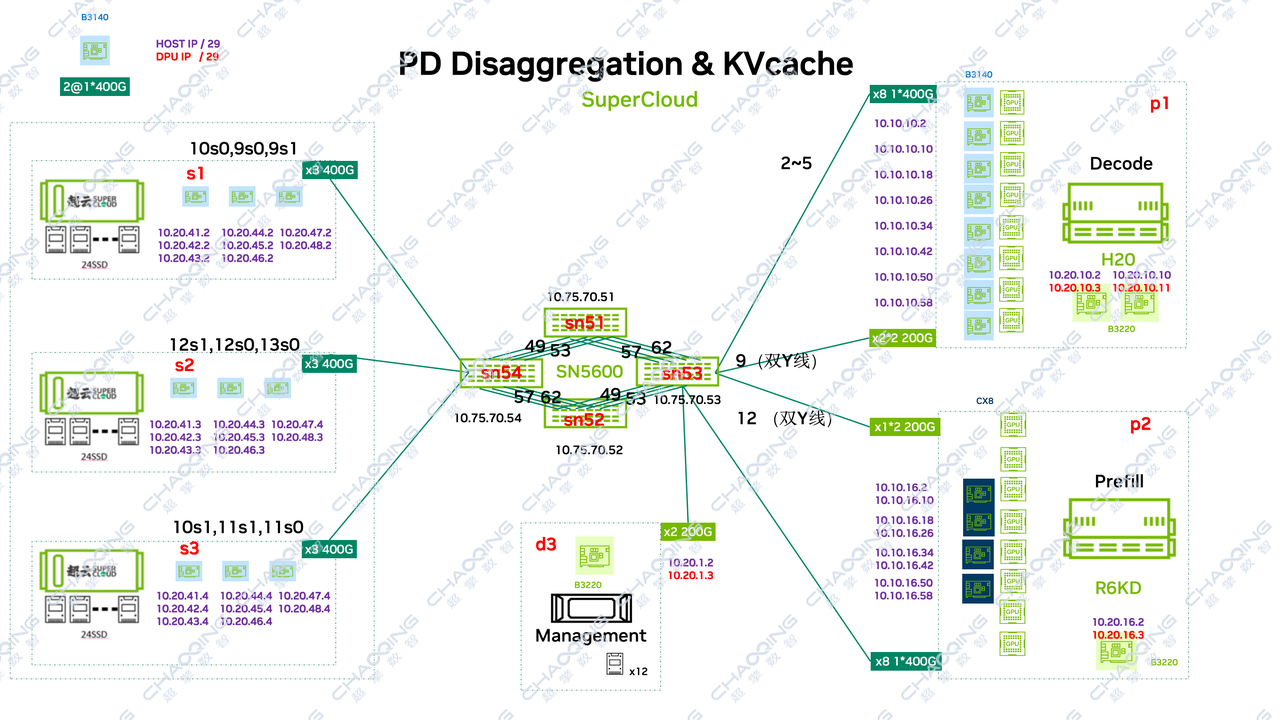
04 测试配置:覆盖全序列输入场景,确保可复现
我们设定了从短到长(100至50000 Token)的全序列输入场景,并采用固定并发与速率进行压测,确保数据可比性。
基础输入参数
核心执行脚本(以PD模式为例)
测试分为Prefill-only(仅预填充)、Decode-only(仅解码生成)、PD(完整流程)三种模式,核心执行脚本如下:

脚本功能说明:指定测试模型与数据集、配置并发请求参数、设置输入输出序列长度、保存详细测试结果与元数据,确保测试过程可复现、结果可追溯。
05 测试结果:数据呈现的显著优势与深层洞察
本次测试对比了五种架构方案,涵盖传统耦合架构、KV Cache Offload CPU及三种不同的PD分离组合,并从三个核心维度进行衡量:吞吐量(Throughput)、首Token延迟(TTFT)、单Token生成时间(TPOT)。
整体结果可视化
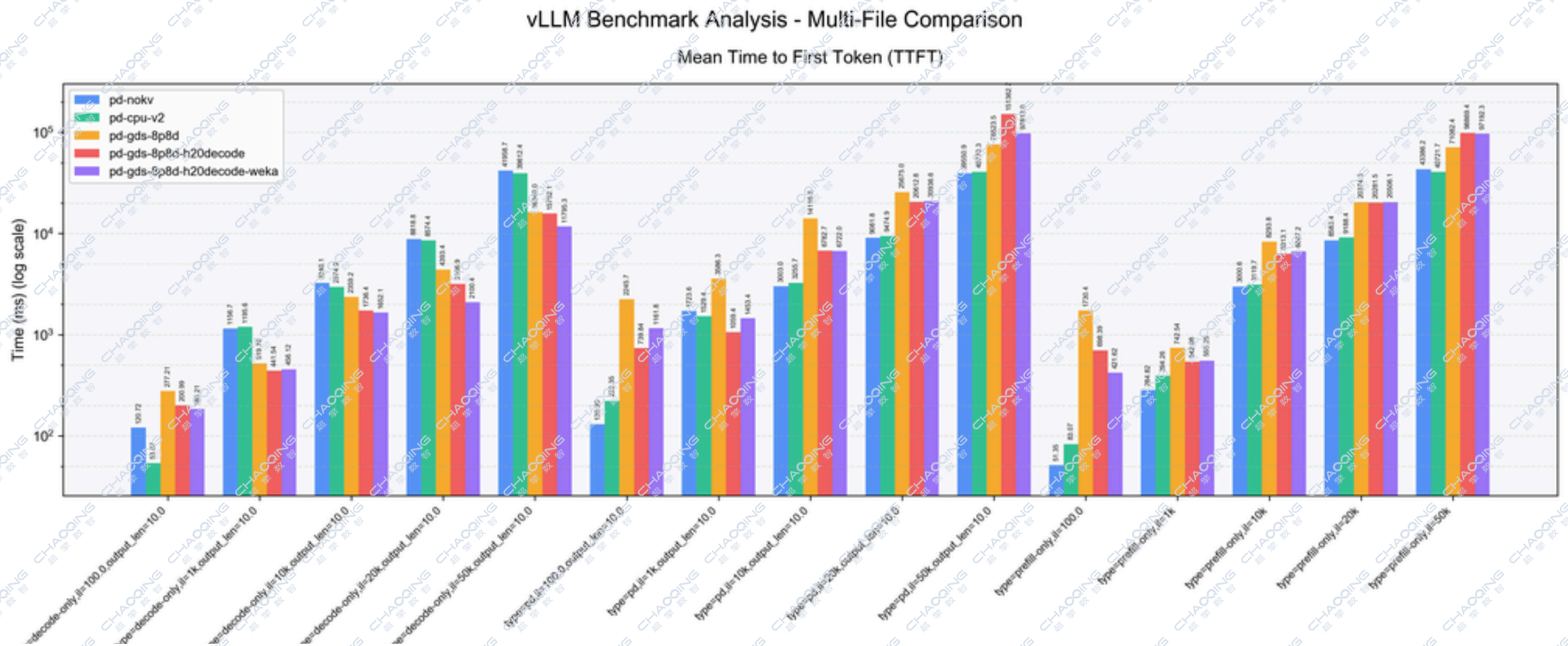
不同输入序列长度下的首Token延迟(TTFT) 指标性能对比
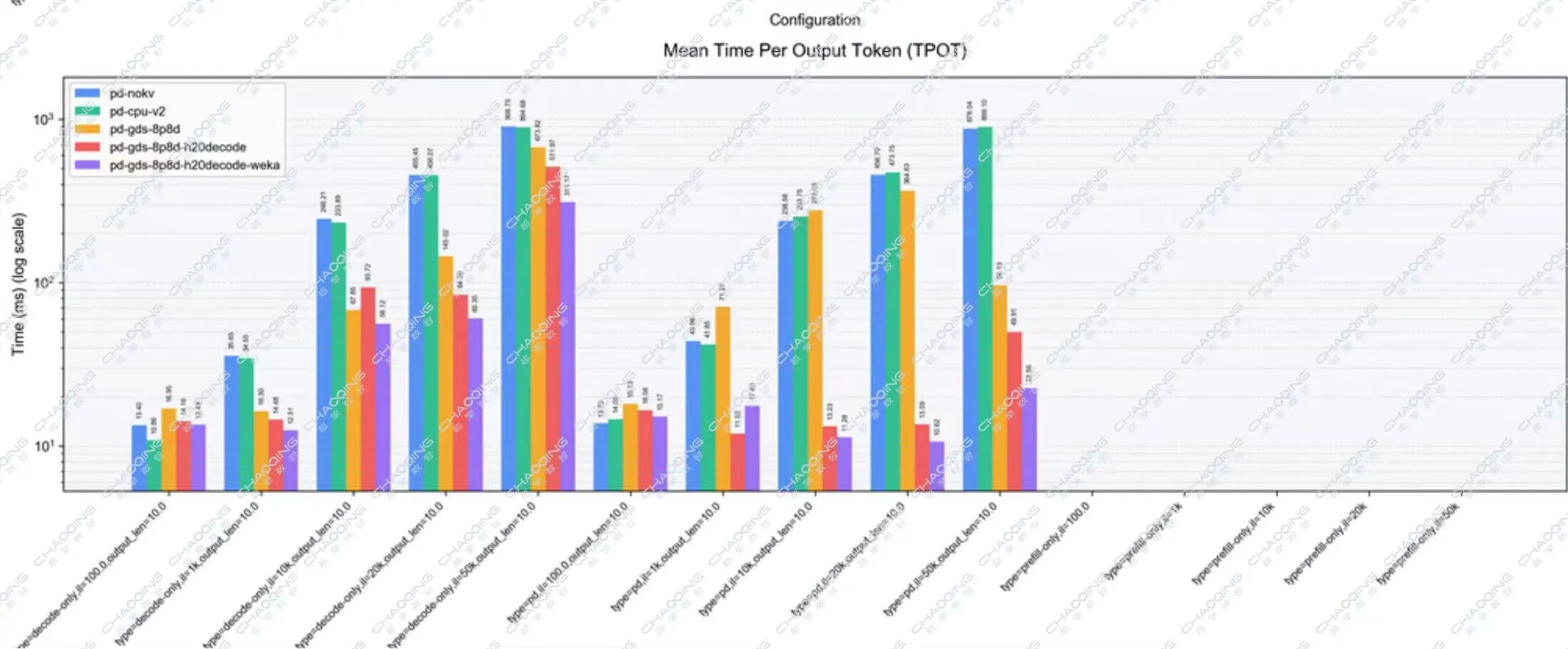
不同输入序列长度下的单Token生成时间(TPOT) 指标性能对比
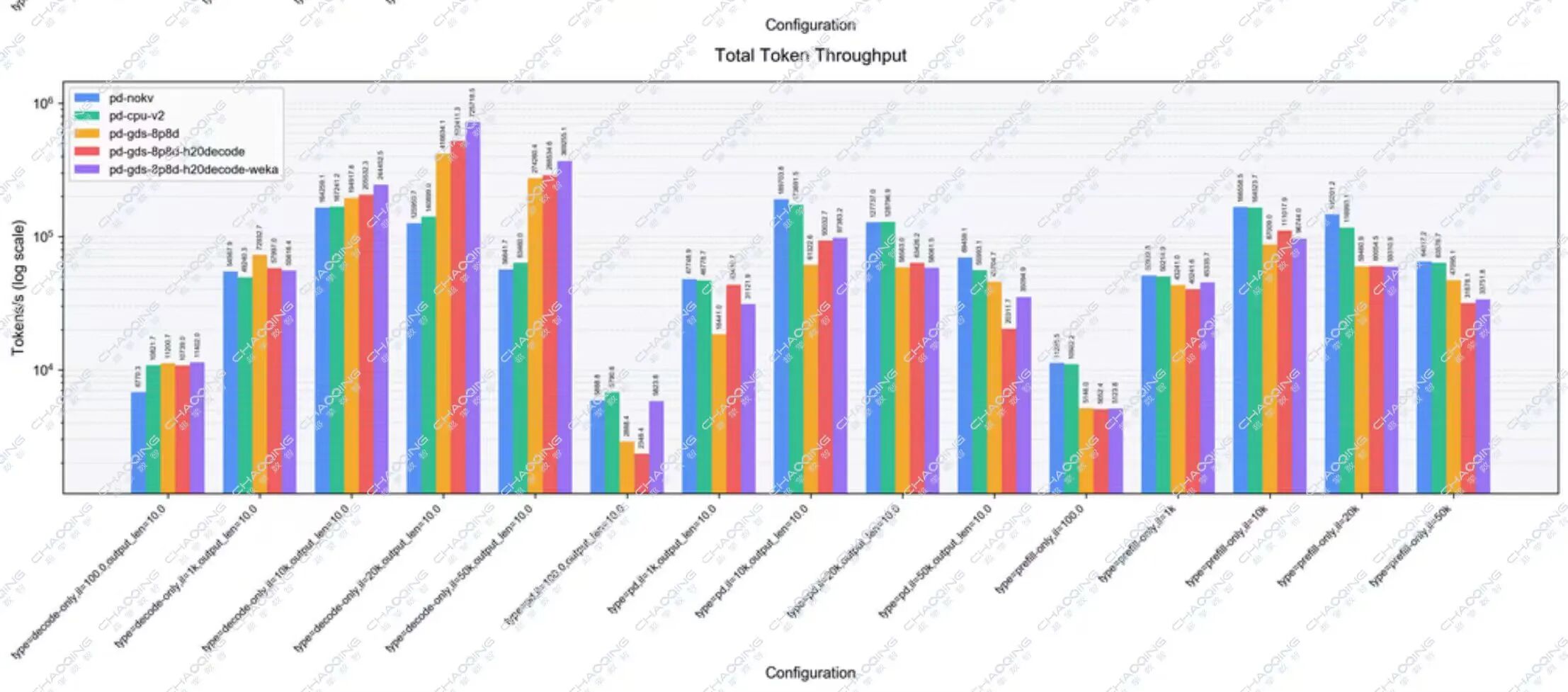
不同输入序列长度下的吞吐量(Throughput) 指标性能对比
核心数据结论
06 结论与展望:超越分离,迈向协同
本次测试最终验证:PD分离架构通过彻底解耦Prefill与Decode阶段,成功消除了计算干扰,在长上下文推理中带来了确定性的、倍数级的性能提升。
同时,数据也揭示了更深层的系统洞察:PD分离架构性能的充分释放,高度依赖于Prefill的供给能力与Decode消费能力能否形成高效流水线。当前在超长上下文(如50K tokens)场景中观察到的性能边际递减,其根源在于,Prefill阶段需同时完成繁重的计算与数据传输任务,导致其供给速率跟不上Decode侧的高吞吐需求,从而形成供给瓶颈。
这为下一代优化指明了方向:未来的突破将不仅仅在于“分离”,更在于 “协同” ——通过更精细的KV Cache调度,更细粒度、流式的生产–消费重叠以及存储后端的持续优化,进一步提升PD分离架构在超长上下文推理中的整体吞吐。
07 总结
本次超擎数智联合 NVIDIA 、超云、DaoCloud、纳多德深度协作的 “PD分离” 与 “KV Cache Offload”系列测试至此圆满收官。我们从理论(上篇)、到关键组件验证(中篇)、再到全架构性能实证(下篇),完整呈现了以 “PD分离” 与 “KV Cache Offload” 为核心的大模型推理优化路径及其巨大潜力。
超擎数智作为AI原生的基础设施整体解决方案提供商,将持续深耕计算、网络与存储的系统级协同创新,致力于将PD分离与KV Cache Offload等前沿技术验证转化为客户可直接部署的、高效稳定的大模型推理解决方案,携手产业生态伙伴不断拓展智能计算与推理应用的技术与价值边界。

公众号


电话

需求反馈
