



















咨询服务热线:400-0698-860
邮箱:info@chaoqing-i.com
业务中心 - 上海超擎数智科技有限公司:上海市徐汇区龙启路158号1幢灿星大厦19层1911
业务中心 - 北京超擎数智科技有限公司:北京市海淀区北三环西路99号西海国际中心1号楼907
研发中心 - 武汉超擎数智科技有限公司:武汉东湖高新区金融港二路9号联发科武汉研发中心2楼





在AI和HPC浪潮席卷全球的今天,数据中心正经历一场前所未有的算力竞赛。GPU的性能持续飞跃,但一个关键瓶颈却常常被忽视——网络。成千上万个GPU之间高效、低延迟的数据流动,才是释放整个集群潜能的命脉。
NVIDIA的ConnectX系列智能网卡始终是这个领域的标杆。ConnectX-7以其强大的400Gb/s性能,奠定了当前AI数据中心网络的基础。然而,随着AI模型的规模和复杂性呈指数级增长,仅仅提升带宽已不足以应对挑战。NVIDIA ConnectX-8 SuperNIC的出现,不是简单的速度升级,而是一次深刻的架构变革。它不仅将网络吞吐量提升至800Gb/s的新纪元,更通过一系列创新的硬件功能,重新定义了网卡在数据中心的角色——从一个被动的数据管道,转变为一个主动、智能的数据处理核心。
一、双重革新:
800G网络与PCIe I/O中枢的完美融合
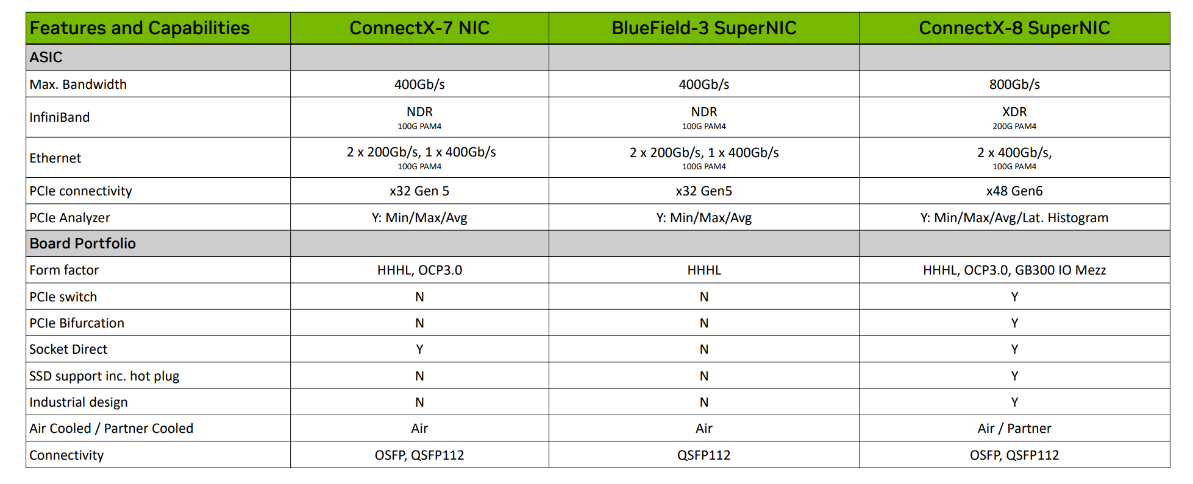
在网络速率和传输能力方面,ConnectX-8实现了翻倍的性能跃升。ConnectX-7最大带宽为400Gb/s,采用100G PAM4信令技术,即每条数据通道(Lane)能传输100Gb/s的速率。而ConnectX-8直接将最大带宽提升至800Gb/s,支持更先进的XDR InfiniBand标准。这一飞跃的背后是底层信令技术的革新:ConnectX-8采用了更前沿的200G PAM4信令,使得单通道速率翻倍。
这项突破在实际应用中意义深远,尤其是在大规模AI训练和HPC(高性能计算)集群场景中。例如,在训练万亿参数级别的巨型语言模型时,GPU间需要进行海量的梯度同步和数据交换,网络通信延迟和带宽成为核心瓶颈。ConnectX-8的800Gb/s带宽能将通信时间减半,显著缩短模型训练周期,从而加快AI技术的迭代速度,并支持更大规模、更复杂的模型并行训练。
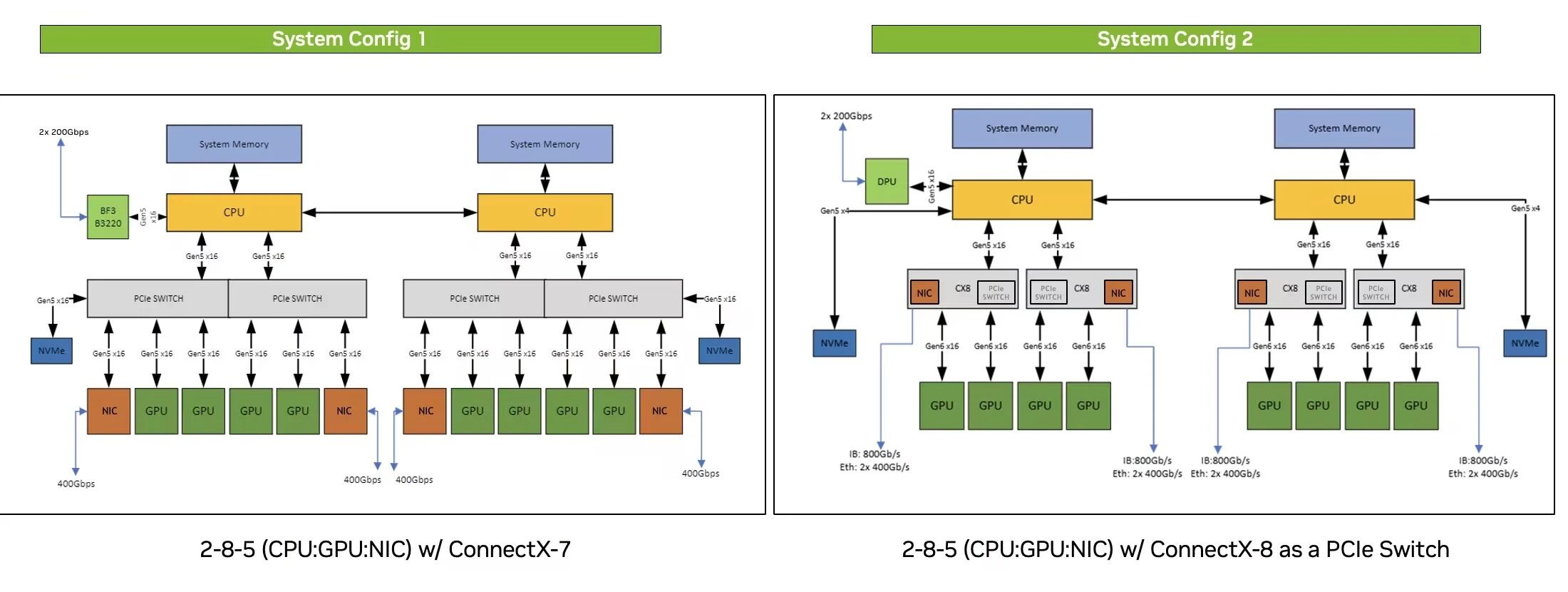
在与主机系统连接方面,ConnectX-8在PCIe接口技术上实现了跨越式的升级,彻底解决了前代产品可能面临的I/O瓶颈。ConnectX-7采用PCIe Gen 5.0 x32接口,理论双向带宽约128GB/s。而ConnectX-8升级到PCIe Gen 6.0 x48接口,总线理论双向带宽高达约384GB/s,是前代的三倍。
更具变革性的是,如图所示,ConnectX-8首次集成了PCIe Switch和Bifurcation(通道拆分)功能。这意味着ConnectX-8不仅是一张网卡,更是一个I/O中枢。在NVIDIA GB200这样的先进计算平台中,一张ConnectX-8卡可以直接通过内置PCIe交换机连接多块GPU或NVMe SSD,极大地简化了系统设计,降低了节点内数据交换的延迟。
这种架构对于构建高密度、高效率的“AI工厂”至关重要,它使得计算、存储和网络三大支柱能够以史无前例的效率协同工作,为数据密集型应用提供了强大的支撑。
二、软硬件协同:
深度加速的技术内核
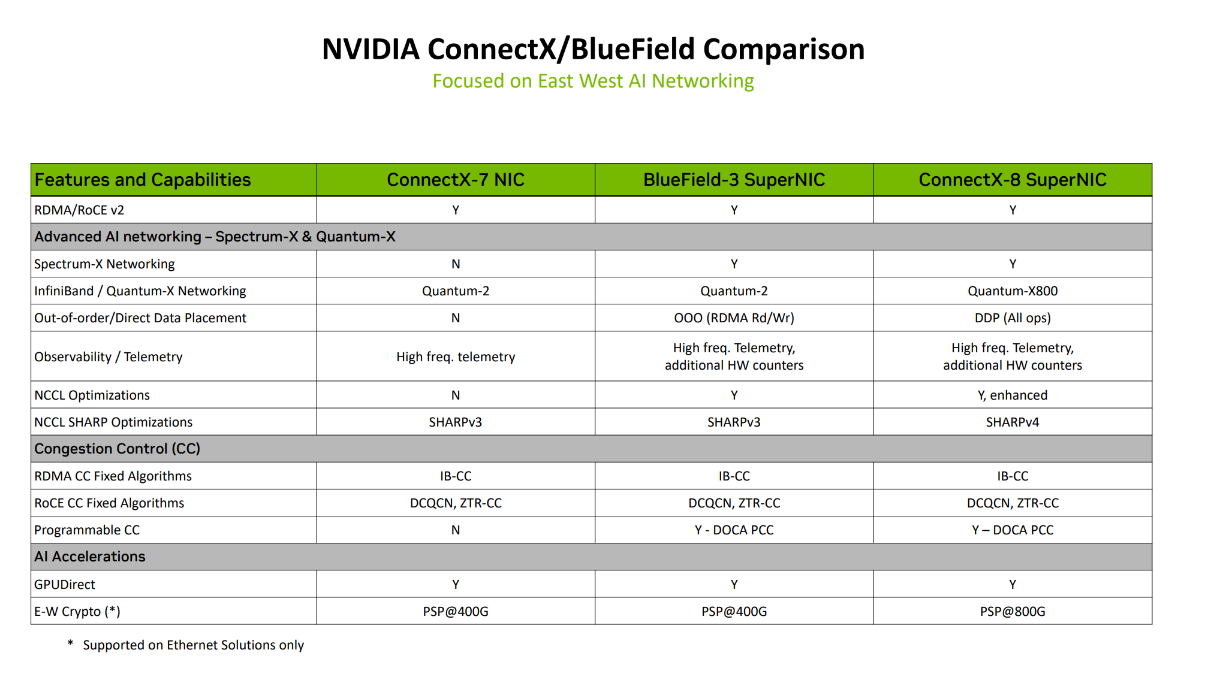
在数据放置技术方面,ConnectX-8实现了从“乱序处理”(Out-of-Order Execution,OOO)到“直接数据放置”( Direct Data Placement,DDP)的质的飞跃。ConnectX-7不支持任何放置技术,ConnectX-8的DDP技术允许网卡在无需CPU干预的情况下,直接将网络数据包精准放置到目标应用程序(如AI训练框架)指定的最终内存地址上。
在训练千亿参数语言模型的应用场景中,节点间需要频繁交换巨大的张量(Tensors)数据。使用ConnectX-8的DDP技术,从其他节点发送的模型梯度或权重数据,能够被直接写入本节点GPU的计算缓存区,大幅度缩短数据从网络到达计算单元的路径,降低端到端延迟,显著提升GPU的有效计算时间占比和整体训练效率。
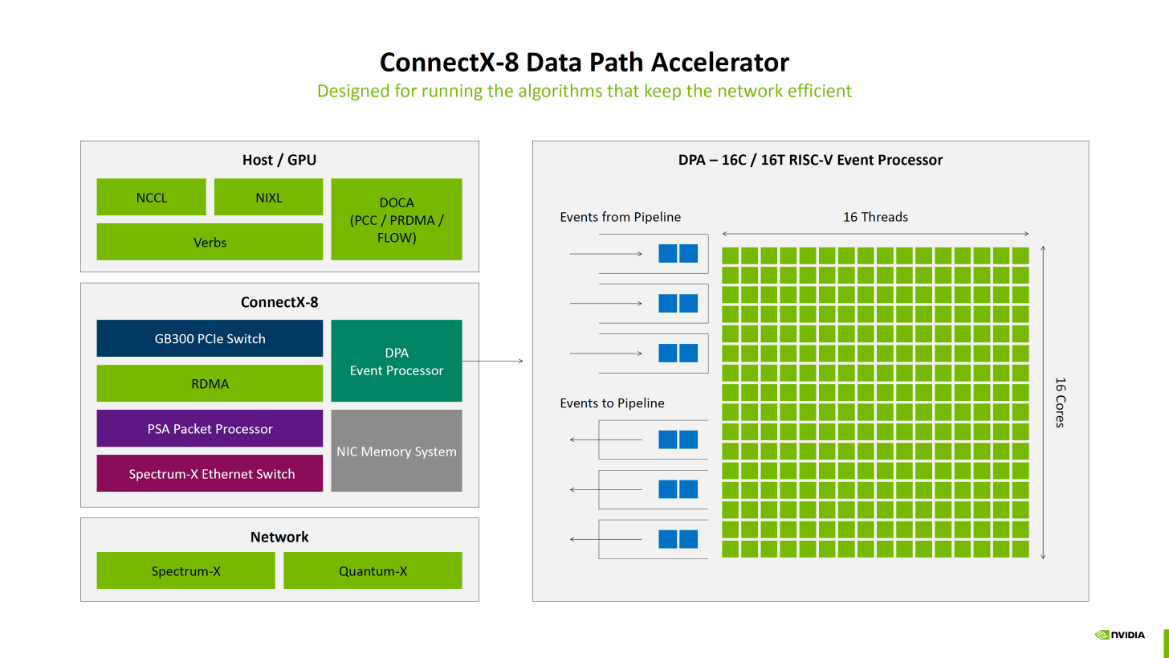
在NCCL SHARP优化方面,ConnectX-8将协议版本从SHARPv3升级到了SHARPv4,这是对网络内计算(In-Network Computing)能力的重大增强。SHARP(可扩展分层聚合与规约协议)技术将原本需要在CPU或GPU上完成的集合通信操作(如All-Reduce,用于同步所有节点的梯度)卸载到网络交换机上执行。当多个节点发送梯度数据时,支持SHARP的交换机会在网络路径中就对这些数据进行聚合(例如求和、求平均),然后再将最终结果分发回各个节点,从而大幅减少需要穿越整个网络的数据总量。
从v3到v4的升级,有着更强的扩展性、更高的算法效率和对更广的数据类型支持。在训练拥有数万个GPU的超大规模集群这一前沿应用场景中,SHARPv4的优势尤为突出。它能够更高效地处理更大规模节点数的聚合通信,减少网络拥塞,并可能支持更高精度的浮点数(如FP32)在网络中直接进行规约操作,保证了模型训练的精准度和稳定性。
在通用的NCCL优化方面,ConnectX-8具备“增强的”NCCL优化,在硬件层面与NCCL软件栈进行了更深度的协同设计。这包括为NCCL特定通信原语(如Send/Recv, Broadcast, All-Reduce)设计的专用硬件数据通路、更智能的硬件任务调度器(能识别并优先处理NCCL流量),以及与GPUDirect技术更紧密的结合。这种软硬件协同设计的目标是最大化“有效带宽”并降低通信操作的“长尾延迟”。在AI推理或需要频繁同步的强化学习等应用场景中,通信延迟的稳定性至关重要。一个节点的偶然高延迟(长尾延迟)就可能拖慢整个集群的步伐。ConnectX-8的增强型NCCL优化通过硬件保障,使得通信延迟更低且更可预测,减少了“掉队者”现象的发生,确保了整个集群计算步调的高度一致性,从而提升了集群整体的有效算力和任务完成速度。
三、智能管控:
可编程以太网的精准操控
在可编程拥塞控制方面,ConnectX-8实现了从“无”到“有”的突破。通过NVIDIA DOCA软件框架实现可编程拥塞控制,网络管理员和开发者可以根据AI工作负载(如All-Reduce、All-to-All)特有的同步、突发流量模式,编写并部署定制化的拥塞控制逻辑。例如,在训练千亿参数语言模型(LLM)的应用场景中,其节点间的梯度交换会产生典型的“Incast”(多对一)流量风暴。利用CX8的DOCA PCC,可以设计一种能预判Incast流量并提前调整发送速率的拥塞算法,主动避免网络拥塞和数据包丢失,避免出现传统算法中拥塞后被动响应局面。显著降低通信延迟的“长尾效应”(tail latency),最终缩短AI模型的整体训练时间。
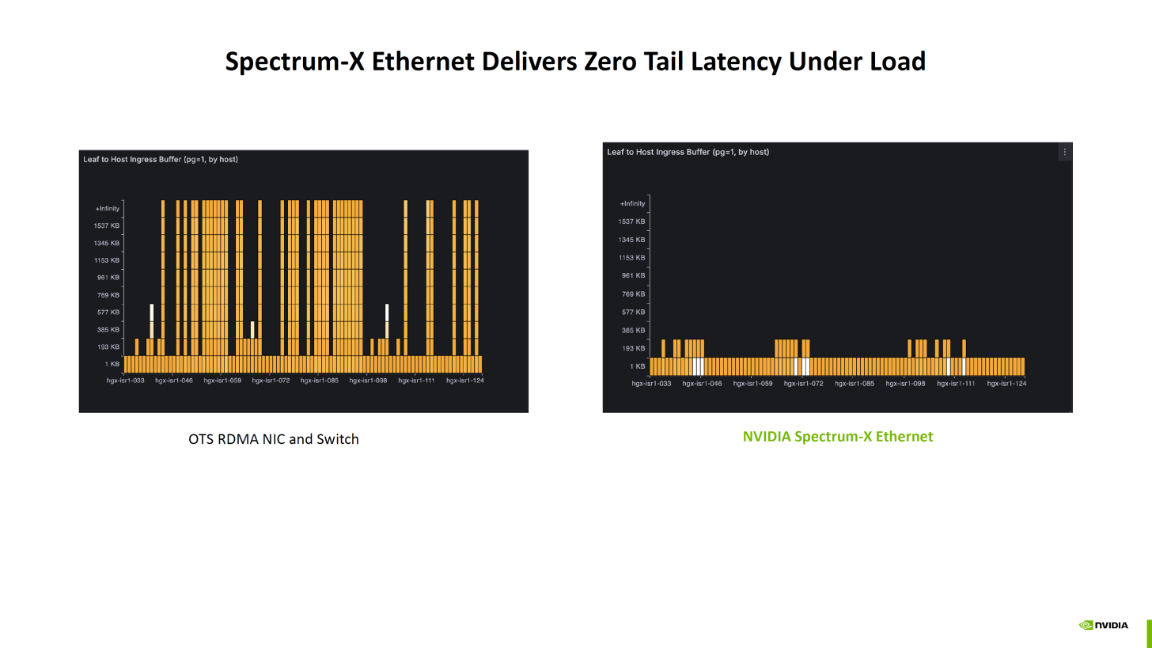
在网络遥测方面,ConnectX-8在ConnectX-7的基础上提供了更深层次、更低开销的洞察能力。图表显示,两者都支持高频遥测,但ConnectX-8明确增加了“additional HW counters”(额外的硬件计数器)。从技术原理上讲,CX7的高频遥测已经能够提供网络流量、延迟等关键性能指标,但更细粒度的事件追踪可能需要消耗主机的CPU资源。ConnectX-8新增的硬件计数器,则是将对特定网络事件(如RoCE NACKs、特定队列的丢包、缓冲区占用等)的监控功能直接固化在网卡芯片(ASIC)中。这种硬件级别的监控几乎实现了零开销,不会占用宝贵的CPU周期,并且能以线速(line-rate)进行超高精度的统计。
在具体应用场景中,当一个大规模分布式AI推理集群出现性能抖动时,传统的遥测可能只能定位到某个节点延迟升高,但难以快速 pinpoint 根本原因。而利用ConnectX-8的额外硬件计数器,运维团队可以精确地看到是不是由于某个GPU的微突发流量导致了网卡出口队列的瞬时拥塞和丢包,从而进行精细化的流量调度或QoS策略调整。这种硬件级的精细洞察力对于保障生产环境中AI服务的SLA(服务等级协议)至关重要。
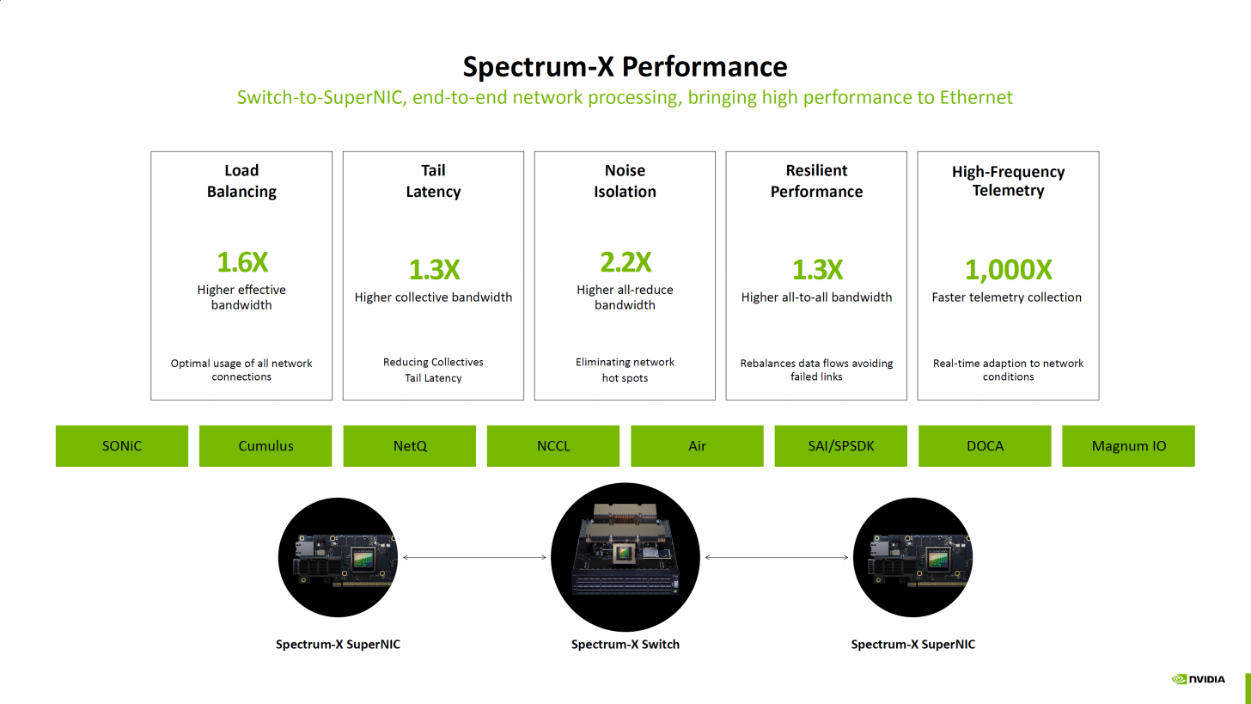
在Spectrum-X网络优化方面,ConnectX-8是原生支持并深度集成的,而ConnectX-7 则不具备此能力。其核心技术理论在于,Spectrum-X并非单一网卡的技术,而是一个集成了ConnectX-8 SuperNIC、BlueField DPU和Spectrum-4交换机的端到端网络平台。它通过软硬件协同设计,实现全网级别的AI负载感知和优化。关键技术包括自适应路由(Adaptive Routing)和性能隔离(Performance Isolation)。平台能够利用从ConnectX-8网卡收集到的精细遥测数据,在交换机层面动态调整数据路径,绕开拥堵节点。
在具体的应用场景中,例如一个多租户的AI公有云环境,一个租户正在运行大规模的数据ETL(提取、转换、加载)任务,产生了巨大的网络流量,可能导致网络热点。如果使用ConnectX-7,这种拥堵可能会影响到邻近节点上另一个租户正在进行的、对延迟极其敏感的AI模型训练任务。而部署了ConnectX-8和Spectrum-X的平台,则可以通过端到端的遥测感知到即将形成的网络热点,并由Spectrum-4交换机主动将AI训练的流量重新路由到更空闲的路径上,从而实现工作负载间的性能隔离,保证了关键AI任务的性能可预测性和稳定性,极大地提升了整个集群的资源利用率和有效吞吐。
开启新时代的智能网络革命
NVIDIA ConnectX-8 SuperNIC的发布,远非一次常规的硬件迭代。ConnectX-7是400G时代的性能标杆,完美完成了数据搬运任务。而ConnectX-8则回答了新的问题:我们能否在数据传输的路径上,进行更智能、更高效的处理?
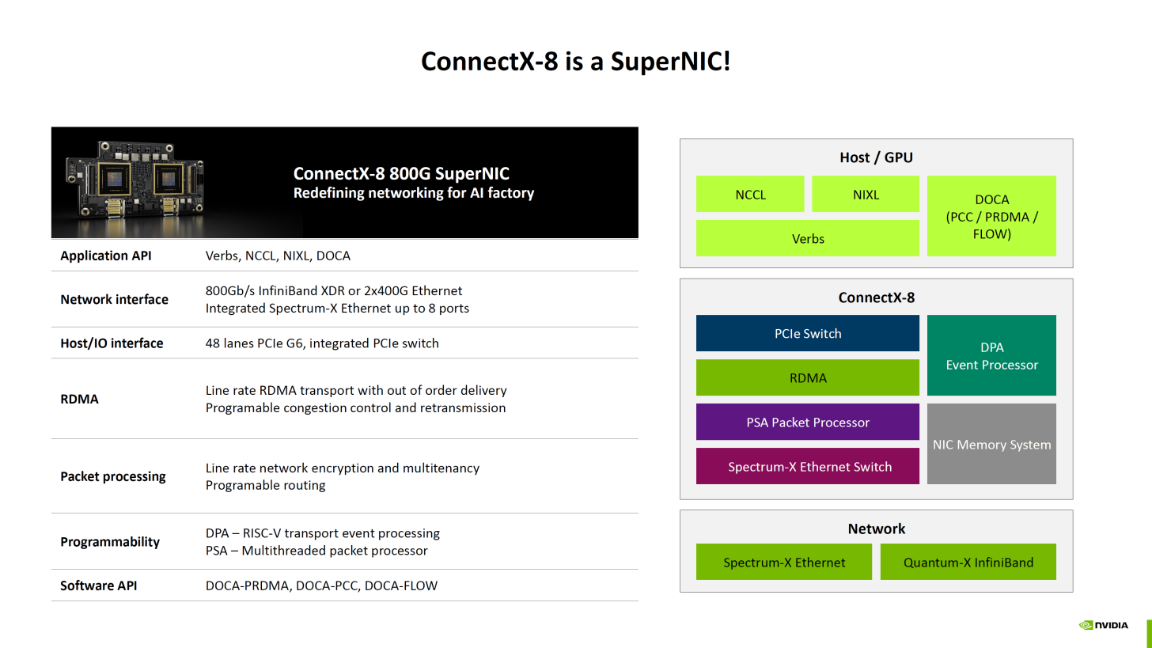
通过800G的澎湃动力、内置PCIe交换与存储的革命性架构,以及为AI量身定制的SHARPv4、DDP和可编程拥塞控制等一系列“超能力”,ConnectX-8将自己打造成AI数据中心中不可或缺的智能节点。它不仅是连接GPU的桥梁,更是分担CPU压力、优化数据流、加速AI工作负载的核心引擎。
超擎数智是 NVIDIA Compute(GPU)、Networking(网络)的双Elite精英级合作伙伴,深度理解AIDC场景下高速网络的核心需求,不仅能够率先提供融合了ConnectX-8 SuperNIC等最前沿技术的端到端解决方案,更能凭借在众多高性能智算中心项目的丰富实践经验,将这份理论上的代际飞跃,转化为数据中心实实在在的算力提升,助力千行百业轻松破除AI算力瓶颈,构建面向未来的智算基石。

公众号


电话

需求反馈
