



















咨询服务热线:400-0698-860
邮箱:info@chaoqing-i.com
业务中心 - 上海超擎数智科技有限公司:上海市徐汇区龙启路158号1幢灿星大厦19层1911
业务中心 - 北京超擎数智科技有限公司:北京市海淀区北三环西路99号西海国际中心1号楼907
研发中心 - 武汉超擎数智科技有限公司:武汉东湖高新区金融港二路9号联发科武汉研发中心2楼





当前AI工作负载的迅猛增长,正不断挑战着全球数百万开发者所依赖的个人电脑和工作站的极限。即使是配备了高端消费级GPU,在尝试运行或微调现代大型语言模型时,也会频繁遭遇“CUDA out of memory”的报错。AI模型的参数量和复杂性,已经远远超过了消费级硬件的增长步伐。这一矛盾迫使部分开发团队转向云端或本地数据中心,却也带来了延迟、数据安全、运维成本等一系列新挑战。
今天,NVIDIA 带来的DGX Spark,正是为彻底构建和运行AI而生的新一代计算机,以小巧的机身形态, 提供高达1 PFLOP 的AI 算力与128GB 统一内存,让开发者能够在本地运行最高 200B 参数的 AI 模型推理,甚至对 70B 参数的模型进行微调。此外,DGX Spark 还支持在本地创建 AI 智能体并运行高级软件堆栈。
强劲的参数预示着强大的生产力。现在,超擎数智技术团队将对 NVIDIA DGX Spark在大型语言模型推理阶段方面的性能进行真机实测,揭晓它如何化身为您桌面上的超强算力。
测试环境
本次测试聚焦于 DGX Spark 在大型语言模型推理阶段的性能表现。系统版本更新为最新,使用专为Spark优化的TensorRT- LLM进行模型部署。
测试数据
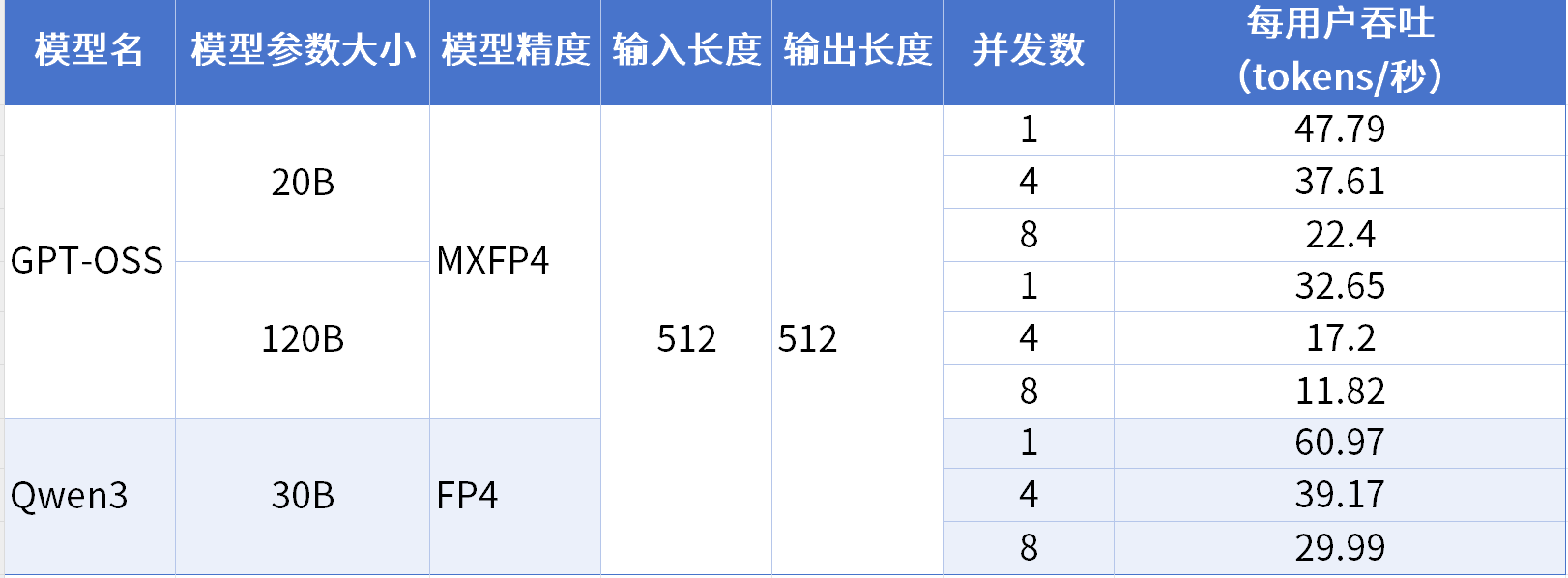
在推理阶段,系统性能主要取决于两个关键指标:

当前 DGX Spark 的 GPU 架构在针对高于 FP4 精度的模型时仍处于持续优化阶段,后续软件与固件更新完成后,将补充更高精度模型的性能数据。
实测表现
本次测试中,DGX Spark成功运行了高达120B(1200亿)参数的 GPT-OSS 模型。充分验证了其128GB统一内存架构的显著优势。开发者现在可以摆脱显存限制,实现对百亿甚至千亿级模型的本地推理和研究。
Prefill性能:瞬时响应,告别首字延迟
Prefill性能对于交互式应用的“首字延迟”(Time to First Token)至关重要,是影响交互体验的关键。DGX Spark凭借1 PFLOP的强大算力、GB10 超级芯片、NVLink-C2C高带宽以及 128GB 统一内存,实现了数据在 CPU 与GPU 间的无缝流动,对输入提示词做到瞬时处理。
Decode速度:效率革命,规避交互卡顿
Decode速度决定了模型的实时交互体验。实测显示, DGX Spark 在120B 的模型上仍能保持32.81 tokens/s 的生成速度,远超流畅对话的阈值。这意味着它不仅是“能运行”大模型,更是能“高效运行”大模型,具备真正的生产级实用价值。
Blackwell 架构 + TensorRT-LLM优化
基于Blackwell 架构对FP4精度的原生支持,配合专为 DGX Spark 优化的 TensorRT-LLM 软件栈,在保持模型准确性的同时,大幅提升了计算效率和吞吐性能。
无缝体验:一栈式桌面级AI工作流
DGX Spark 在一台桌面设备中集成与 NVIDIA 数据中心服务器完全一致的软件栈,包括 CUDA、NVIDIA AI Enterprise 、NIM 微服务以及NVIDIA Blujeprint,为开发者提供了从本地开发到云端部署的统一环境。
开发者可以在 DGX Spark 上完成模型的原型设计与测试,并无缝迁移到 RTX Pro Server等数据中心平台上进行大规模部署,从而大幅降低迁移与适配成本。
超擎数智作为 NVIDIA Compute(GPU)、Networking(网络)的双Elite精英级合作伙伴,拥有专业的交付与技术支持团队,将全力以最快速度将NVIDIA DGX Spark交付至用户手中,并提供从部署调试到技术支持的全链条服务,保障用户无缝对接世界顶级算力,助力AI开发者抢占技术创新先机。

公众号


电话

需求反馈
