



















咨询服务热线:400-0698-860
邮箱:info@chaoqing-i.com
业务中心 - 上海超擎数智科技有限公司:上海市徐汇区龙启路158号1幢灿星大厦19层1911
业务中心 - 北京超擎数智科技有限公司:北京市海淀区北三环西路99号西海国际中心1号楼907
研发中心 - 武汉超擎数智科技有限公司:武汉东湖高新区金融港二路9号联发科武汉研发中心2楼





随着单细胞测序(scRNA-seq)在生命科学研究中的快速发展,数据规模呈指数级增长。在真实科研场景中,20万级别细胞数量已逐渐成为常态。
这也意味着,传统基于CPU的分析流程,在处理大规模数据加载、邻接图构建、降维与聚类时,往往捉襟见肘,耗时漫长且容易因内存不足而中断。
当数据规模遇上算力瓶颈,如何破解?
近期,超擎数智技术团队基于DGX Spark,结合RAPIDS-singlecell加速框架,对一组208000+细胞的公开数据集(数据来源:见文末“阅读原文”)进行了端到端的全流程测试。
超擎数智将用实测数据揭示:在高性能算力的加持下,单细胞分析可以有多高效、多稳定。
测试背景
本次测试,旨在验证DGX Spark在处理大规模生物信息数据时的性能表现、可用性与科研适配性。超擎数智技术团队选取了极具代表性的CELLxGENE公开数据集,并采用了GPU加速方案与传统CPU方案进行对比。
测试用例直接选了公开的、具有代表性的大数据集:
核心优势
在传统的Scanpy(CPU)流程中,当细胞规模提升至十万级以上时,PCA降维与邻接图构建等计算密集型步骤往往成为整体分析效率的主要瓶颈。而在本次DGX Spark的测试中,我们实现了从数据加载到下游分析的无缝衔接,重点体现在以下三个阶段:
海量吞吐,秒级加载
使用AnnData将超过20万个细胞的数据加载至内存,并直接在GPU可支持的数据结构上进行后续处理,DGX Spark依然保持了极高的数据吞吐效率,为后续计算打下坚实基础。

矩阵运算,极速降维
在最耗时的预处理环节,包括质量控制(QC)、归一化以及PCA降维阶段,涉及大规模的运算。利用GPU的并行计算能力,我们极大地压缩了计算时间。
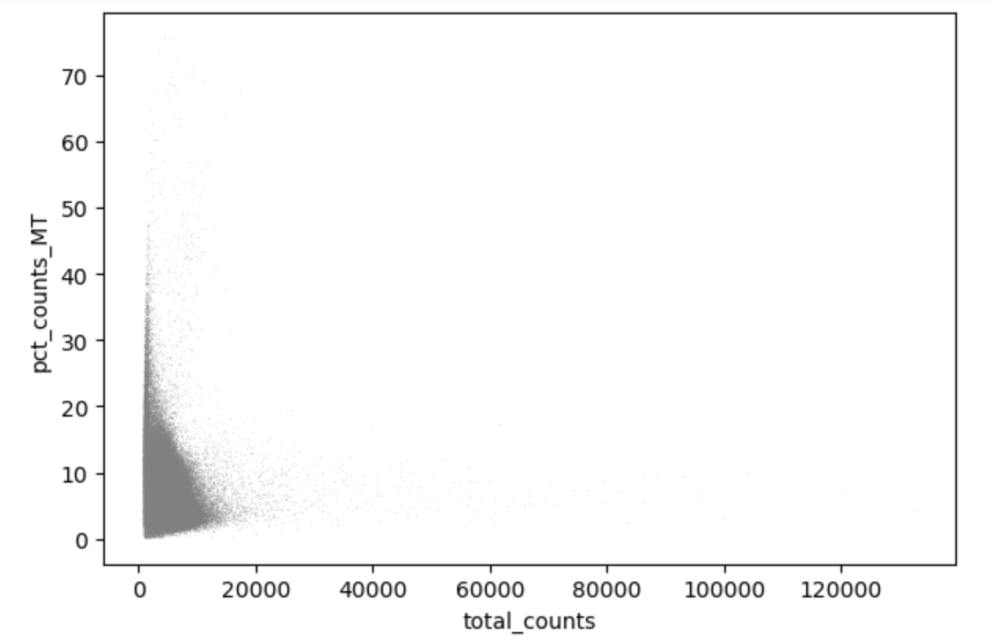
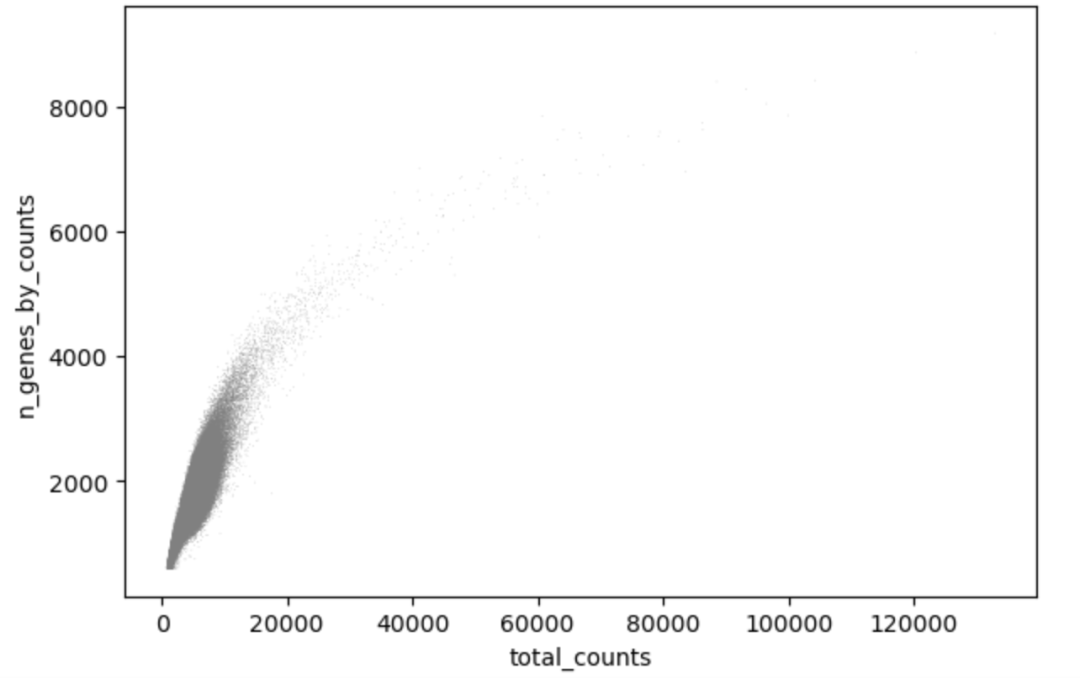
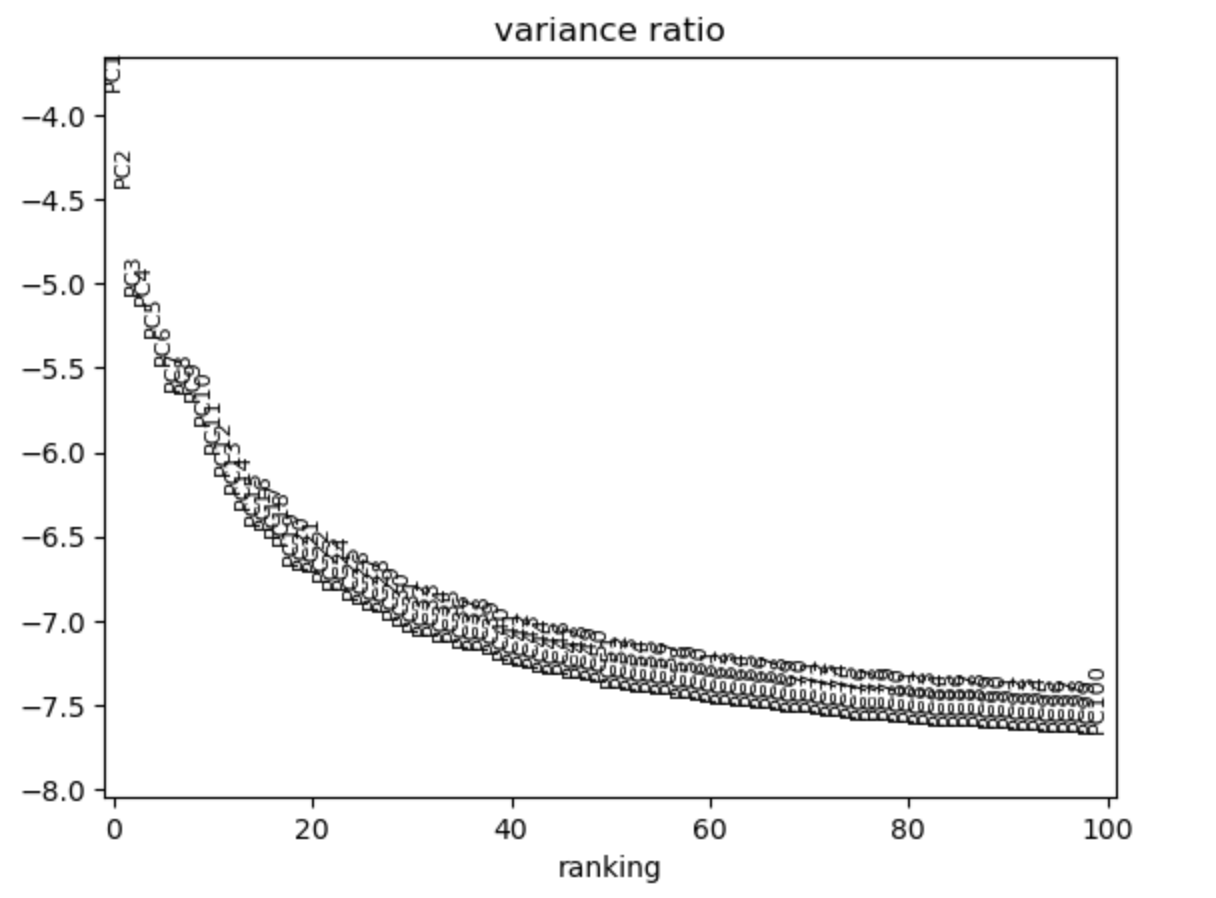
复杂分析,交互体验
测试进入深水区,涵盖KNN邻接图构建、UMAP可视化、Louvain / Leiden聚类以及批次效应矫正。实测显示,即使在20万级细胞规模下,构建KNN图和UMAP低维嵌入的过程依然流畅。这不仅是速度的提升,更意味着科研人员可以实时调整参数,快速查看聚类效果,无需漫长等待。
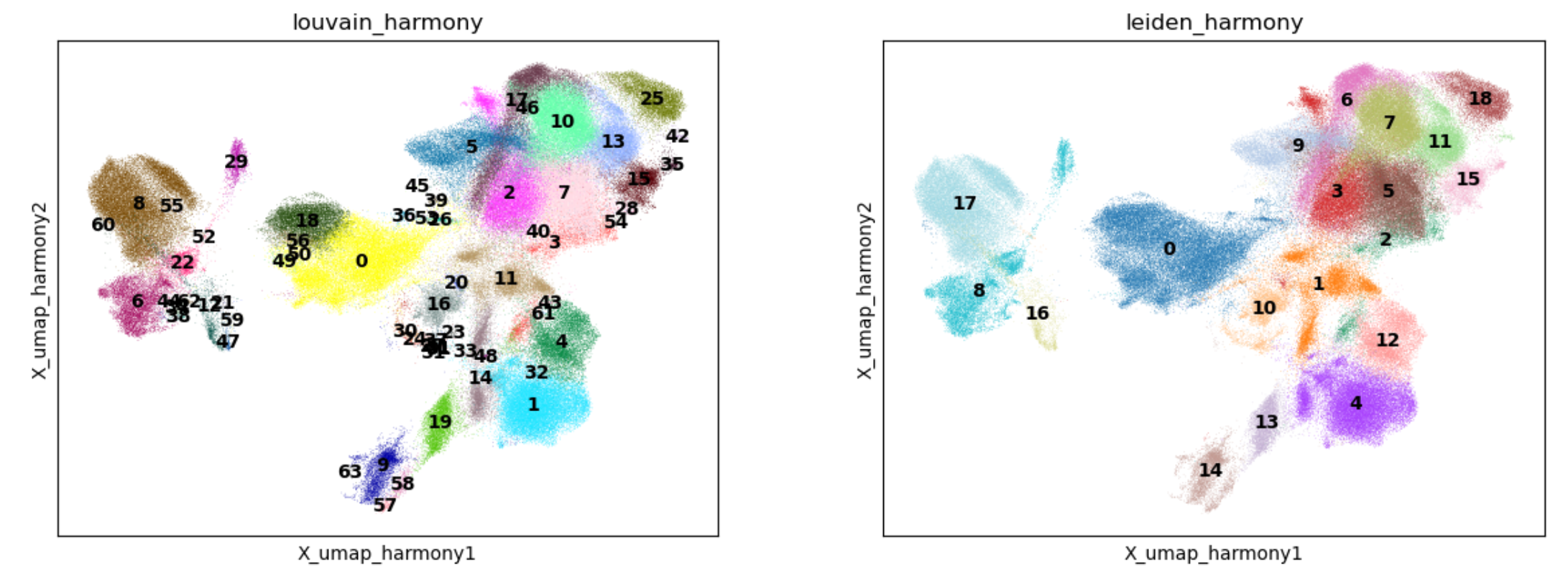

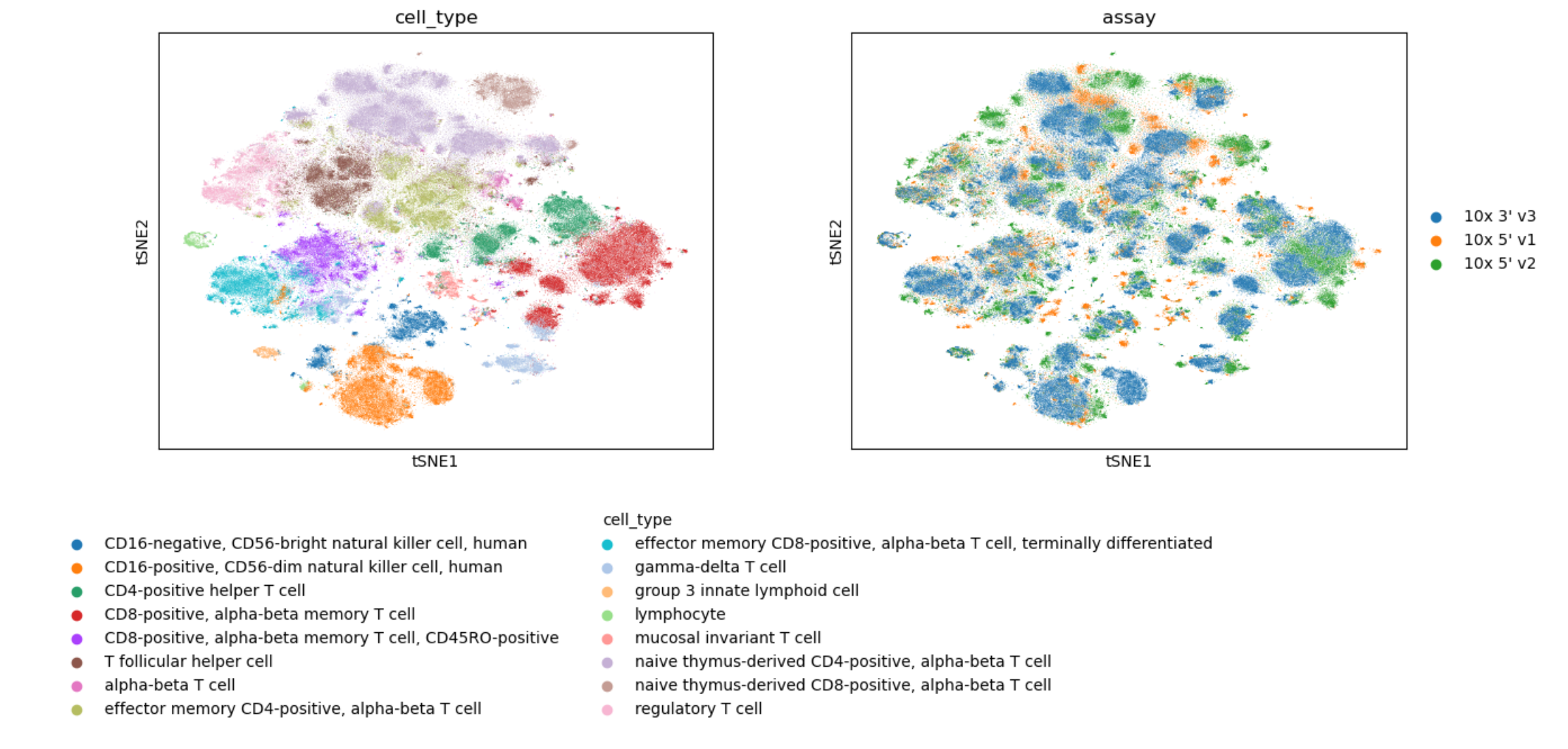
深度探索 不止于快
速度只是基础,深度挖掘才是目的。基于聚类结果,超擎数智技术团队进一步在DGX Spark上执行了差异表达分析与Diffusion Map。得益于强大的算力储备,团队能够迅速探索潜在的细胞发育轨迹或状态变化,为揭示复杂 生物学机制提供精准的数据支持。

测试总结
通过本次scRNA-seq全流程测试,DGX Spark展现出了卓越的性能优势:
这一解决方案尤其适用于高校科研机构、生物制药及生信平台建设。它让科研人员从繁琐的等待中解放出来,将宝贵的时间投入到算法验证、新方案开发与生物学意义的解读中。
作为AI原生的基础设施整体解决方案提供商,超擎数智深知,在AI For ALL时代,单一硬件提供已不足以应对指数级增长的数据挑战,唯有软硬融合的全栈优化才是破局关键。从底层网络设计到上层应用优化,超擎数智能为千行百业客户提供全栈式服务,解决算力瓶颈、消除数据孤岛、提升集群效率,共同探索智能未来的无限可能。

公众号


电话

需求反馈
