



















咨询服务热线:400-0698-860
邮箱:info@chaoqing-i.com
业务中心 - 上海超擎数智科技有限公司:上海市徐汇区龙启路158号1幢灿星大厦19层1911
业务中心 - 北京超擎数智科技有限公司:北京市海淀区北三环西路99号西海国际中心1号楼907
研发中心 - 武汉超擎数智科技有限公司:武汉东湖高新区金融港二路9号联发科武汉研发中心2楼





随着人工智能技术从通用大模型向垂直行业深耕,算力基础设施领域正迎来一场以“极致性能”为核心的代际变革。当万亿级参数训练成为常态,数据规模的指数级增长对底层网络的吞吐能力提出了前所未有的挑战,行业正加速跨入“全800G互联”时代。
近日,超擎数智凭借深厚的技术沉淀,成功交付InfiniBand XDR 800G端到端高性能网络方案,以800G的巅峰速率,消除数据传输壁垒,为高性能智算集群注入最强动力。
行业痛点:分布式训练的网络瓶颈
支撑这一数智化转型的背后,是极其庞大的算力挑战。AI大模型的训练任务天然具有强通信特征,在分布式训练过程中会产生高频、突发且持续的集体通信与参数同步流量。
对于智算基础设施建设者而言,面临着三大核心痛点:
超擎解决方案:端到端InfiniBand XDR 800G极致互联
针对上述痛点,超擎数智构建了面向AI训练的InfiniBand XDR超低时延网络解决方案。该方案以 NVIDIA InfiniBand XDR为核心,建立起高吞吐、可规模扩展的互连网络架构。
客户服务案例:极致精细的标准化交付
在本次为客户交付高性能GPU集群的过程中,超擎数智不仅提供了高性能的硬件方案,更通过标准化的交付体系,将“工程”提升为“工艺”,确保高性能网络真正落地。
工业级标准的严苛交付:
从开箱验收到设备上架,超擎数智技术团队执行了极为严苛的工业级实施标准。针对高密度智算中心对环境的敏感性,团队实现了从防静电控制、风道气流优化到毫米级线缆管理的精细化作业。特别是在网络布线环节,通过严格的信号干扰控制与弯曲半径管理,确保了高速线缆的正常传输,为集群的长期稳定运行打下物理基础。
实测787Gbps!XDR 800G性能满血释放:
基于高性能GPU集群架构对带宽的需求,超擎数智对InfiniBand XDR网络进行了深度的性能调优。通过GPU Direct RDMA技术启用与PCIe 6.0链路优化,在交付验收环节中实现了惊人的性能突破:GPU-网卡-交换机-网卡-GPU 的全链路测试中,实测带宽高达787Gbps。这一数据接近800G物理线路的理论极限,完美验证了XDR网络在复杂拓扑下的超高吞吐能力,消除了大规模分布式训练中的通信瓶颈。

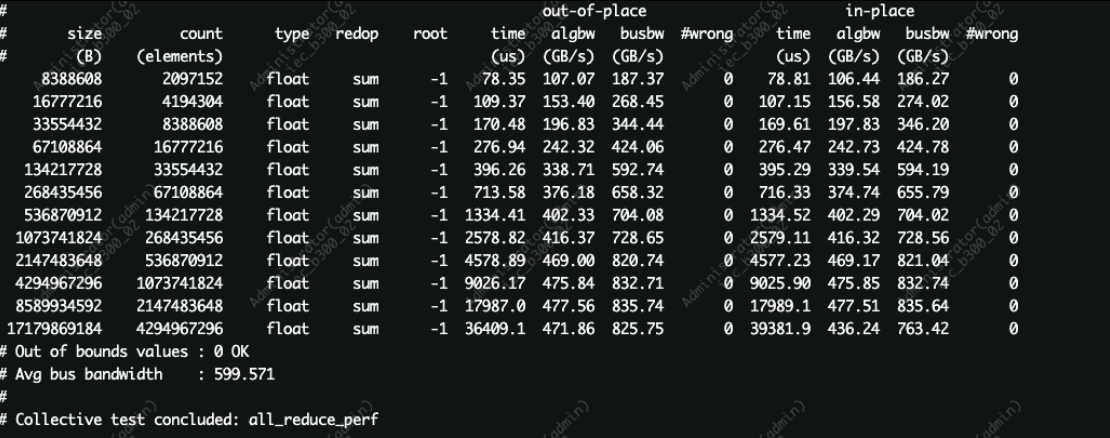
性能验证:NCCL测试表现
为进一步验证网络在真实AI训练场景中的效能,超擎数智对集群的NCCL集合通信性能进行了测试,测试结果展现出极佳的吞吐效率与稳定性,能有力支撑训练任务的高效执行。
全栈优化,赋能高效开发
为了帮助客户快速从“集群部署”切换至“模型训练”状态,超擎数智同步部署了AI Engine人工智能开发平台。提供从数据预处理、模型微调到可视化推理部署的一站式工具链,助力客户将安全大模型的迭代周期大幅缩短。
结语
本次高性能GPU集群的完美交付,不仅验证了超擎数智在下一代超大规模智算网络建设上的深厚积淀,更标志着在前沿算力架构落地能力上迈上了新的台阶。
在AI技术极速演进的今天,算力是核心生产力,网络则是决定算力释放效率的生命线。超擎数智将持续聚焦高性能计算与人工智能基础设施领域,坚持以“创新技术+专业部署”双轮驱动,致力于消除网络瓶颈,为客户打造稳固、高效、可线性扩展的算力底座,让每一份算力都能转化为驱动业务创新的澎湃动能。

公众号


电话

需求反馈
