



















咨询服务热线:400-0698-860
邮箱:info@chaoqing-i.com
业务中心 - 上海超擎数智科技有限公司:上海市徐汇区龙启路158号1幢灿星大厦19层1911
业务中心 - 北京超擎数智科技有限公司:北京市海淀区北三环西路99号西海国际中心1号楼907
研发中心 - 武汉超擎数智科技有限公司:武汉东湖高新区金融港二路9号联发科武汉研发中心2楼





随着大模型训练、推理和多模态AI应用持续演进,AI基础设施正在从单机算力竞争,进入超大规模GPU集群系统能力竞争的新阶段。
在这一阶段,企业关注的不再只是GPU数量、单卡性能或交换机带宽,而是整个集群能否在更大规模下保持低时延、高吞吐、强稳定和可持续扩展。对于万卡、十万卡级AI集群而言,网络互联能力已经成为决定GPU利用率、训练效率和整体建设成本的关键变量。
在传统数据中心中,布线长期被视为基础工程环节。但在AI集群中,布线已不再只是“连接设备”,而是决定网络拓扑能否成立、链路质量能否稳定、集群规模能否扩展的重要基础能力。光学Shuffle架构,正是在这一背景下成为大规模AI网络建设中的关键技术方向。
1、传统布线正在成为AI集群扩容瓶颈
大规模AI训练与推理业务高度依赖GPU集群的高速通信,对网络架构提出了超高带宽、超低时延、全互联高密度组网的严苛需求。传统数据中心采用一对一端口直连模式,面对AI集群的通信需求,暴露出三个结构性缺陷:
第一,三层网络架构转发跳数多,尾部时延长,无法满足低时延算力调度要求。
第二,为实现交叉互联只能依靠人工跳纤,数千根光纤无序堆叠,损耗波动大,800G/1.6T高速链路容易产生误码。
第三,缺乏标准化拓扑规则,故障定位困难,每次扩容都需要大规模重新布线。
上述问题的根源在于:传统布线无法将单个高速光模块的多条光通道拆分并分发至多个目标设备。这正是光学Shuffle技术要解决的核心命题。
2、Shuffle技术在现代网络架构扩容的重要作用
通道Shuffle技术正被应用于人工智能网络中,以在降低成本和功耗的同时提升性能。通道分离能够实现更精细的多路径负载均衡(Packet Spraying),从而提高网络可靠性。与三层叶脊核心网络相比,两层叶脊网络可节省两跳交换机,从而降低网络对尾部延迟的影响。两层网络通常比三层网络减少40%的交换机和50%的光纤收发器。如果包含GPU叶光模块,则总收发器数量可减少约33%。

在现代AI大规模算力集群中,Shuffle技术通过光学通道重组,从根本上打破了传统网络架构硬性分割的Pod边界,将孤立的小规模网络整合为逻辑上完全扁平的无阻塞统一资源池。这一架构变革不仅使网络能够在同等硬件条件下承载数倍于传统方案的GPU规模,也通过丰富的多路径选择避免了跨Pod通信的拥塞与高时延,有效降低训练任务的尾部时延并提升吞吐率。同时,Shuffle显著减少了所需交换机、收发器及光纤数量,在提升网络容错能力的同时降低了单位算力的成本与功耗,是支撑万卡乃至十万卡级AI集群高效运行的核心技术基础。
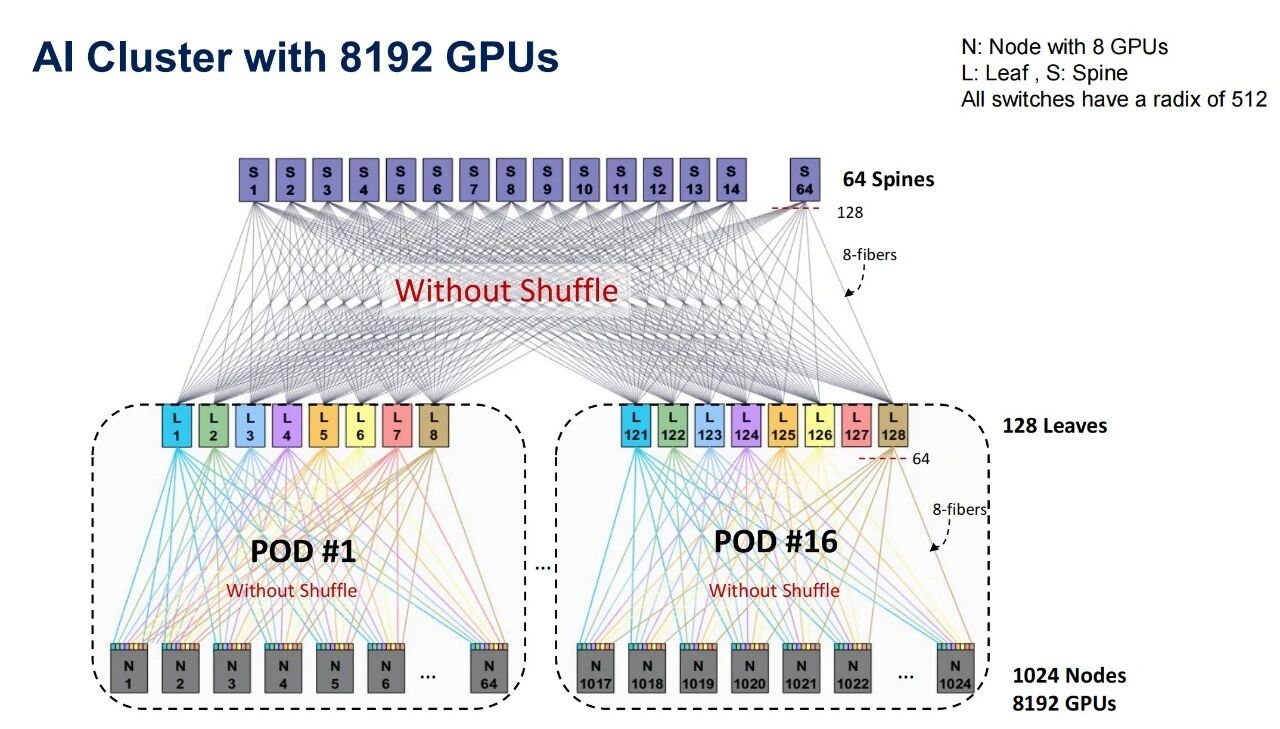
(1)未使用shuffle技术
图1展示了在同样使用512端口交换机的条件下,未采用Shuffle技术的传统两层叶脊架构被严格分割为16个独立的Pod,将集群限制在共8192个GPU的规模。且每个叶交换机只能与固定的脊交换机建立一对一静态连接,跨Pod流量必须经过多级转发,这也导致了网络实际上无法形成一个逻辑统一的资源池,多路径负载均衡效果差,端到端通信的尾部时延也随之增加。
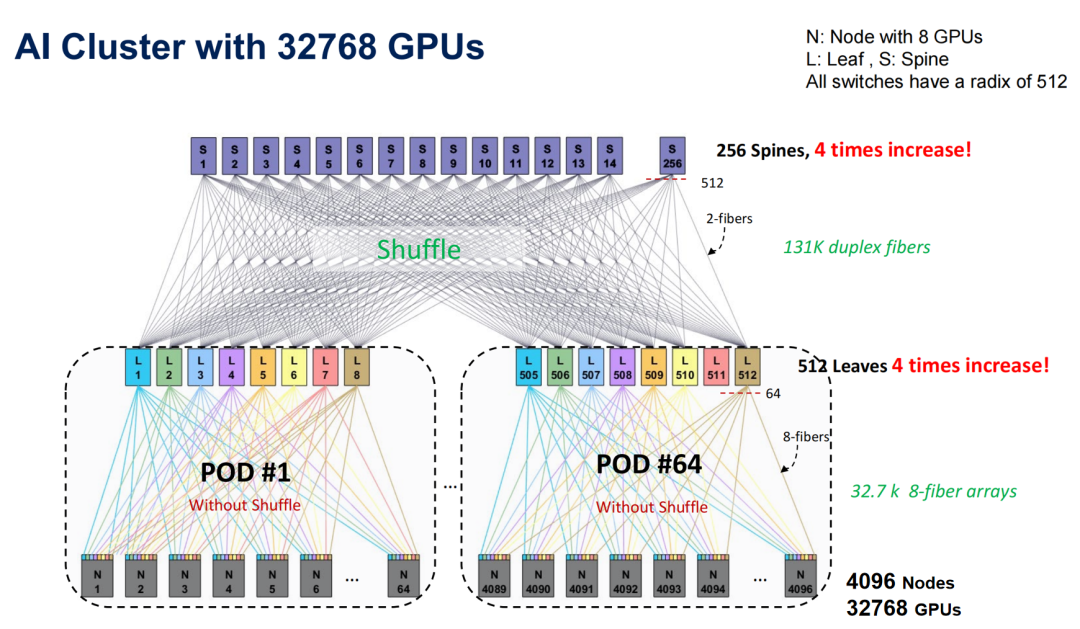
(2)仅在交换机间用shuffle技术
对比未使用Shuffle技术时,网络被严格分割为16个独立Pod、只能支持8192个GPU的局限,引入Shuffle架构后,如图2所示,集群不仅在规模上跃升4倍达到32768个GPU。通过双工跳线将GPU光通道打散并均匀分发至所有交换机,Shuffle彻底打破了硬性Pod边界,使原本相互孤立的网络片区整合为一个逻辑上完全扁平的无阻塞统一资源池,从而在消除跨Pod通信瓶颈、优化多路径负载均衡、降低尾部时延与单位算力网络成本等方面实现了结构与性能的双重突破。
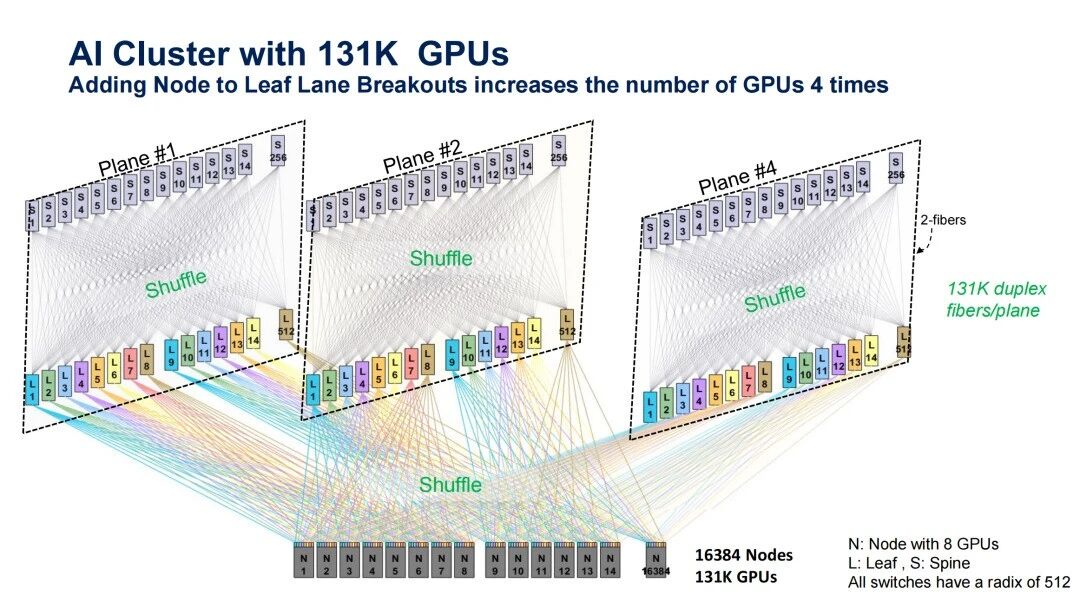
(3)四平面组网
在交换机间使用Shuffle已将单平面集群提升至3.2万GPU的基础上,如图3所示,该架构将Shuffle的起点从交换机侧进一步下沉至计算节点出口,每个GPU的光模块在源头即被拆分为多条通道,形成四平面组网。这一设计使集群在不改变512端口交换机硬件的前提下,规模再次跃升4倍,达到13.1万GPU。
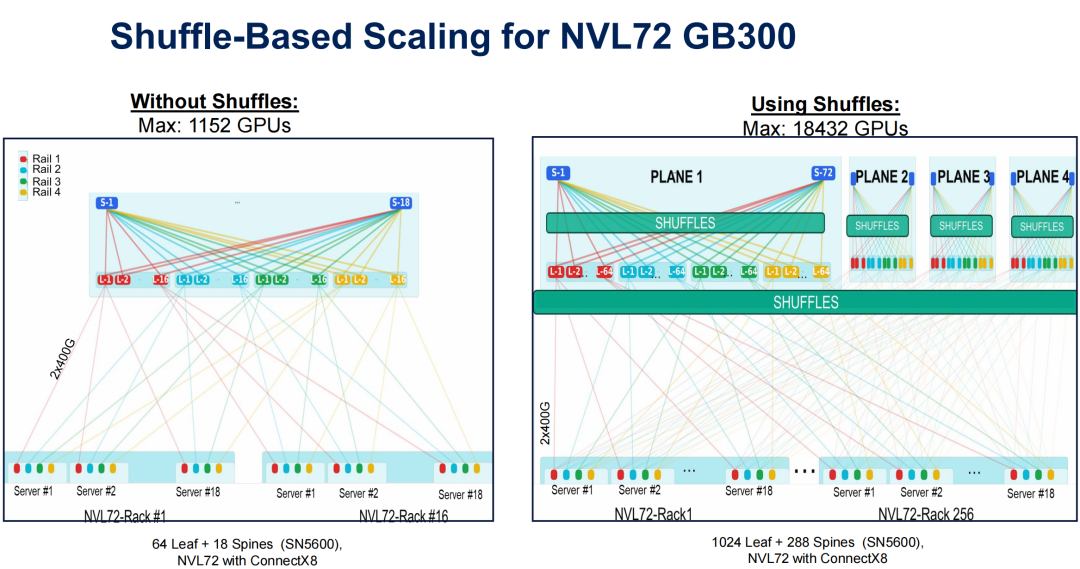
(4)GB300 使用Shuffle架构前后网络架构对比
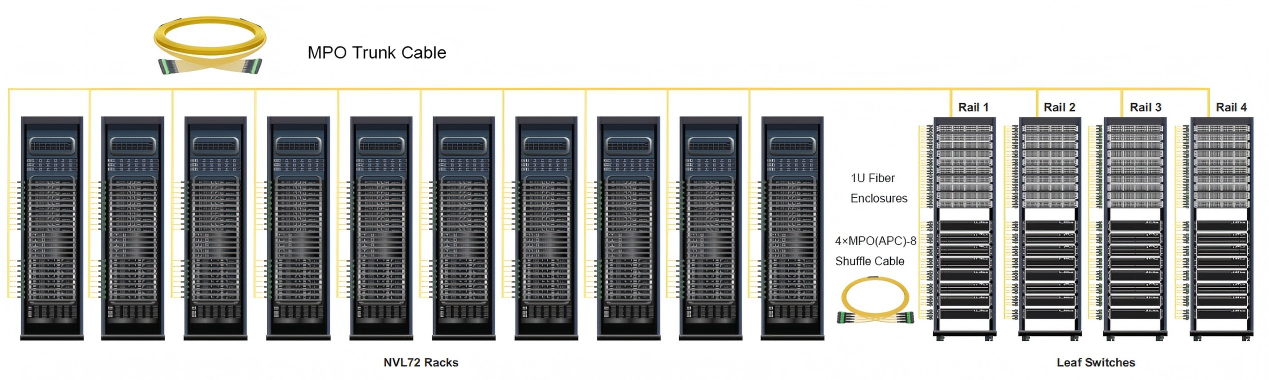
以NVIDIA GB300 NVL72为例,传统直连布线下单集群最多承载1152个GPU。更换定制4x4 Shuffle Cable后,单集群GPU数量提升至18432个,扩容能力增长16倍。每个GPU通过以2×400G运作的ConnectX-8网络卡连接,通道被breakout和shuffle以创造丰富的连接网状结构。
3、传统布线过程中存在的问题
在万卡至十万卡级AI集群中,传统多芯MPO跳线无法独立实现Shuffle拓扑。原因在于,所有标准MPO跳线内部光纤序位均遵循固定极性标准,本质上仍是一对一直通连接,只能将全部光通道原封不动搬运,无法在跳线内部完成通道的拆分、交叉与重组。而Shuffle架构要求将一个光模块的多条通道打散后分发至不同交换机端口,这恰恰是标准MPO跳线物理层能力无法覆盖的。
因此,现场施工一度只能退回到用大量双工跳线逐根手动映射的原始方案。但这立即引发三重工程灾难:一是百万级端口基数下人工差错不可避免,拓扑崩溃风险极高;二是海量线缆无序堆积形成“线缆瀑布”,堵塞风道、故障难寻;三是手工端接的一致性与清洁度不足,无法满足800G链路对损耗的苛刻要求,误码成为常态。
正是为了终结这一困局,Shuffle Cable与Shuffle Box作为预制化解决方案应运而生。前者将拓扑映射关系在工厂内预制于缆身内部,用一根标准化跳线替代现场成百上千根双工跳线的手动编排;后者将更复杂的多平面、高密度Shuffle Cable集成于模块化盒体,为交换机内部及核心配线区提供可复制的拓扑固化方案。二者共同将光通道重排从不可控的现场手工操作,转化为可控的工厂预制工序,是支撑十万卡级集群从“不可建”走向“可交付”的唯一工程化路径。
4、超擎数智Shuffle解决方案:Shuffle Cable & Shuffle Box



(5)超擎数智高密度及超高密度Shuffle Cable(16F/32F/256F)
Shuffle Cable在出厂前已完成内部光纤序位重排,预先标准化Shuffle Mapping。通过预定义的光纤映射关系与多路径连接设计,可有效简化高密度网络中的交叉布线,降低部署复杂度与运维风险,同时为AI训练、HPC等对时延高度敏感的业务持续提供稳定、高性能的网络连接。它主要应用于机柜之间、ToR交换机横向对接、GPU节点跨柜交叉链路、主干链路、AI多平面网络架构部署等场景。

(6) 超擎数智高密度Shuffle Box
Shuffle Box专为大规模AIDC多平面结构化布线架构设计,通过高密度模块化设计有效简化AI数据中心的部署与扩展。产品具备低于0.35dB的超低插入损耗,可确保高速网络环境下稳定可靠的光传输性能;推拉式结构支持快速、免工具安装与维护,兼容标准EIA 19英寸机架,并可在4U空间内实现最高1024 芯光纤部署。基于8芯并行光架构设计,实现100%光纤利用率,在提升端口效率的同时有效降低整体布线成本。
应用示例
Shuffle Cable
Shuffle Box

注:服务器与交换机之间连接需要使用光模块,光模块型号需根据实际需要选择
5、布线层正在成为AI基础设施竞争的关键环节
光学Shuffle技术正在从传统意义上的网络优化手段,演进为超大规模AI基础设施中的关键能力。
它不仅突破了传统网络架构的规模限制,使更高效的两层网络和多平面网络成为可能,也通过减少交换机、光模块和光纤数量,帮助AI数据中心降低资本支出和运营成本。更重要的是,丰富的路径选择、更低的尾部时延和更高的网络容错能力,将直接影响GPU集群的整体效率。
随着AI集群持续向万卡、十万卡乃至更大规模演进,物理层互联将不再只是数据中心建设中的辅助环节,而是与GPU、交换机、存储系统同等重要的基础能力。
对于正在建设大规模AI基础设施的企业而言,理解并合理部署光学Shuffle架构,已经成为提升AI集群规模、效率、稳定性和成本竞争力的重要前提。
未来,AI基础设施竞争将走向系统级工程能力竞争。超擎数智将持续依托在AI全栈方案领域的领先实力,帮助行业客户构建更高效、更可靠、更可持续扩展的新一代AI基础设施底座。

公众号


电话

需求反馈
