



















咨询服务热线:400-0698-860
邮箱:info@chaoqing-i.com
业务中心 - 上海超擎数智科技有限公司:上海市徐汇区龙启路158号1幢灿星大厦19层1911
业务中心 - 北京超擎数智科技有限公司:北京市海淀区北三环西路99号西海国际中心1号楼907
研发中心 - 武汉超擎数智科技有限公司:武汉东湖高新区金融港二路9号联发科武汉研发中心2楼





过去两年,大模型应用的重心正在快速从“训练”转向“推理”。越来越多的团队开始在本地或私有环境中部署模型:代码助手、知识库问答、企业 Agent、RAG 系统、数据分析助手……这些场景有着严苛的共性需求:模型必须持续稳定运行,且需要处理越来越长的上下文。
然而,当真正开始部署时,很多团队都会遇到同一个瓶颈:显存。
模型规模在增长,上下文长度在增长,并发请求在增长,显存很快就会触碰天花板。模型跑得通,但上下文一长,延迟就直线上升;并发量一多,吞吐和稳定性就开始波动;为了把模型“塞”进服务器,不得不采用做更激进的量化方案。量化虽能显著降低计算资源消耗、提升推理速度,但也存在若干技术性弊端,会导致模型输出准确性下降、对异常值敏感等。
在此背景下,大显存GPU正成为推理基础设施中的关键组件。
今天,超擎数智技术团队将依据实测数据,为您解析基于最新Blackwell架构的RTX PRO 5000,72GB GDDR7 ECC显存、2000 TFLOPS AI算力、搭载新一代Tensor Core与更高显存带宽,它将如何为模型推理提供更从容的运行空间?
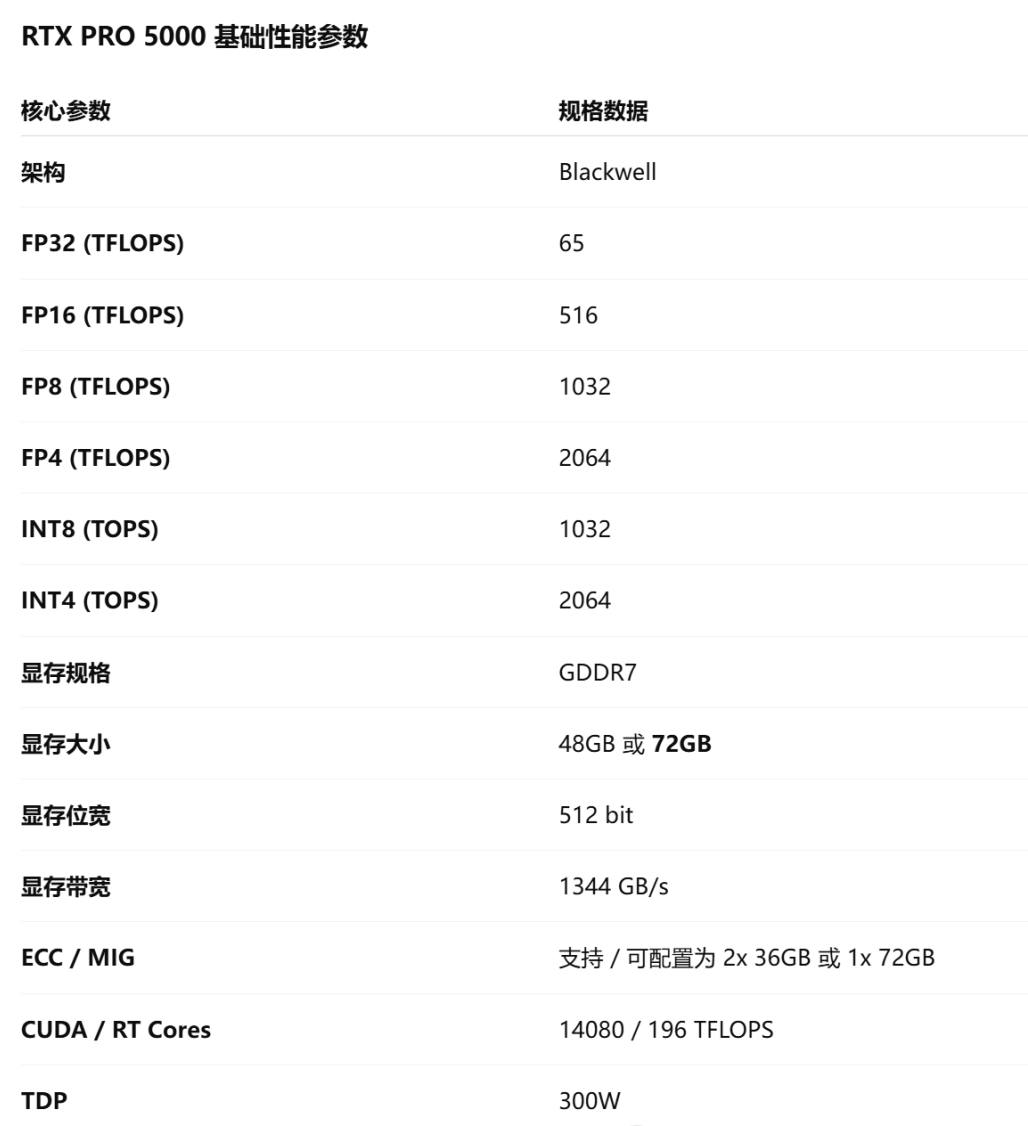
一、性能解密:Blackwell架构加持,算力与显存的双重升级
RTX PRO 5000基于 NVIDIA 最新的Blackwell架构,在算力、显存以及带宽等方面均实现了明显提升。其FP8与FP4等低精度算力能够达到更高水平,使其在AI推理场景中能够提供更高的吞吐能力。
测试解析
RTX PRO 5000采用GDDR7显存,72GB大显存不仅意味可以部署参数量更大的模型,配合1344GB/s的显存带宽,更能为长上下文推理和更高并发请求,提供更充足的缓存空间。
同时,MIG技术的加持,让GPU资源分配更加灵活。在多用户推理服务或多任务场景下,MIG可以将单张GPU划分为多个独立实例,从而提升资源利用率。
二、性能实测:通信与推理的双重考验
本次测试在超擎数智擎天系列CQ7458-L AI服务器平台上完成。该平台面向AI微调与推理场景设计,能支持高密度GPU部署,并通过优化的PCIe拓扑结构为GPU之间提供高带宽、低延迟的数据交换路径。
测试环境:GPU驱动版本590.48.01,CUDA版本13.1
Part.1通信测试:多卡协同的“高速公路”
在多GPU AI计算中,GPU间的数据交换效率直接影响系统的扩展上限。
GPU P2P带宽测试
P2P通信允许GPU绕过CPU内存进行数据交换,从而显著降低通信延迟并提升带宽。
在多GPU推理场景中,P2P通常是数据交换的基础路径,因此其带宽和延迟表现会直接影响多卡协作效率。
在本次测试中,我们对 RTX PRO 5000之间的P2P带宽进行了测试,结果显示RTX PRO 5000展现了极低延迟与高带宽特性:
单向带宽:54.97 GB/s
双向带宽:105.29 GB/s
延迟:0.39 us
NCCL 集合通信测试
在实际负载中,AllReduce(数据聚合)和All-to-All(MoE 架构中的 Token 重分配)是最核心的通信模式。依托超擎数智擎天系列CQ7458-L AI服务器的底层拓扑优化,其实测表现十分优异:
AllReduce:43.52 GB/s
All-to-All:38.74 GB/s
这表明,即使在复杂的MoE大模型推理任务中,该架构依然能保证Token分发与汇聚的高效无阻。
Part.2模型推理:从容应对高并发与长文本
为了进一步评估 RTX PRO 5000在实际AI推理场景中的表现,超擎数智技术团队基于vLLM 0.17.0推理框架,对多个主流大模型进行了多场景推理测试。
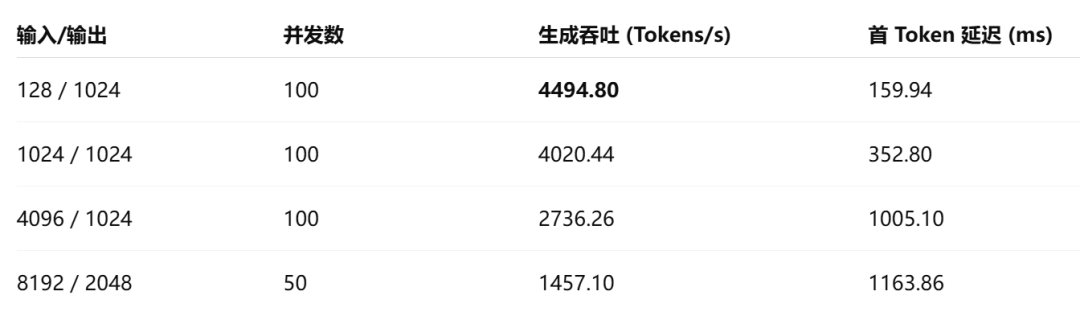
场景一:Qwen3-30B-A3B-FP4(单卡实测)
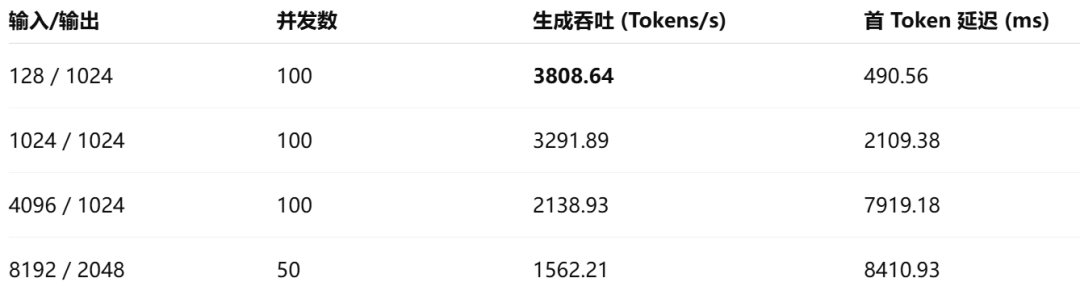
场景二:Qwen3.5-35B-A3B-FP8(单卡实测)
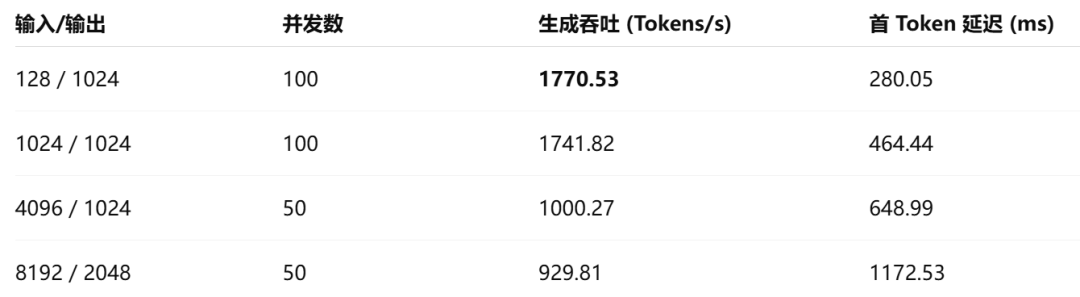
场景三:Qwen3-235B-A22B-FP4(4卡实测)
测试解析
单卡实力强劲:面对中等规模的模型(如 Qwen3-30B、Qwen3.5-35B),RTX PRO 5000单卡即可轻松实现数千Tokens/s的吞吐量,且首Token延迟极低,深度契合实时交互类应用(如智能客服、实时翻译)的需求。
无惧上下文:尽管超长输入不可避免地带来了Prefill(预填充)阶段的计算开销,但得益于72GB容量与1344GB/s的高带宽,模型在长上下文生成阶段依然保持了极其稳定的吞吐表现。
卓越的多卡扩展性:在面对235B的超大规模模型时,4卡协同展现出了出色的线性扩展能力。这证明其在多GPU推理环境下,完全具备支撑企业级核心业务的能力。
三、超擎优势
好马配好鞍,顶级的GPU需要顶级的技术服务配套来释放潜能。
作为 NVIDIA Compute(GPU)与 Networking(网络)的双 Elite 精英级合作伙伴,超擎数智不仅为您提供单点设备,更能依托在AI数据中心、无损网络、高性能计算领域的深厚积淀,为您构筑全栈AI服务护城河。
深度协同,构筑全栈闭环:我们不仅提供擎天系列CQ7458-L等高性能AI服务器,更深度构建无损网络架构与高速光电联接方案。通过端到端的系统级优化,确保从单机到大规模集群的性能呈线性稳步提升。
千万级研发测试投入,确保落地无忧:依托自建的高性能计算与人工智能研发测试中心、NVIDIA 授权的 DPU 和 DOCA 卓越中心,在RTX PRO 5000规模化部署前,超擎数智已联合生态伙伴完成了千万级资源的跨厂商协同验证。
全生命周期赋能,降低部署门槛:从前期的算力规划、架构选型,到中期的部署实施,再到后期的运维调优,超擎数智能提供全生命周期的专业技术支持,懂产品,更懂服务,助力客户的AI应用快速、稳定走向生产环境。
RTX PRO 5000 72GB的出现,无疑为大模型推理基础设施树立了新的标杆。它不仅解决了企业在AI落地时的“显存焦虑”,更凭借强大的底层架构带来了效率的全面跃升。
在万物互联的数智时代,超擎数智将持续以领先的研发和技术服务能力,携手前沿算力产品,为千行百业在数字经济浪潮中的业务加速与产业创新,提供最坚实的基础支撑!

公众号


电话

需求反馈
