


















咨询服务热线:400-0698-860
邮箱:info@chaoqing-i.com
业务中心 - 上海超擎数智科技有限公司:上海市徐汇区龙启路158号1幢灿星大厦19层1911
业务中心 - 北京超擎数智科技有限公司:北京市海淀区北三环西路99号西海国际中心1号楼907
研发中心 - 武汉超擎数智科技有限公司:武汉东湖高新区金融港二路9号联发科武汉研发中心2楼





当我们谈论 AI 基础设施时,多数人首先关注的是 GPU 算力:多少张 H100、NVLink 带宽有多高、单卡 FLOPS 提升了多少。然而,在实际生产环境中,尤其是当 AI 计算规模从“单一数据中心”扩展到“跨园区、跨城市的 AI 工厂(AI Factory)”时,真正决定系统效率上限的往往是网络能力。
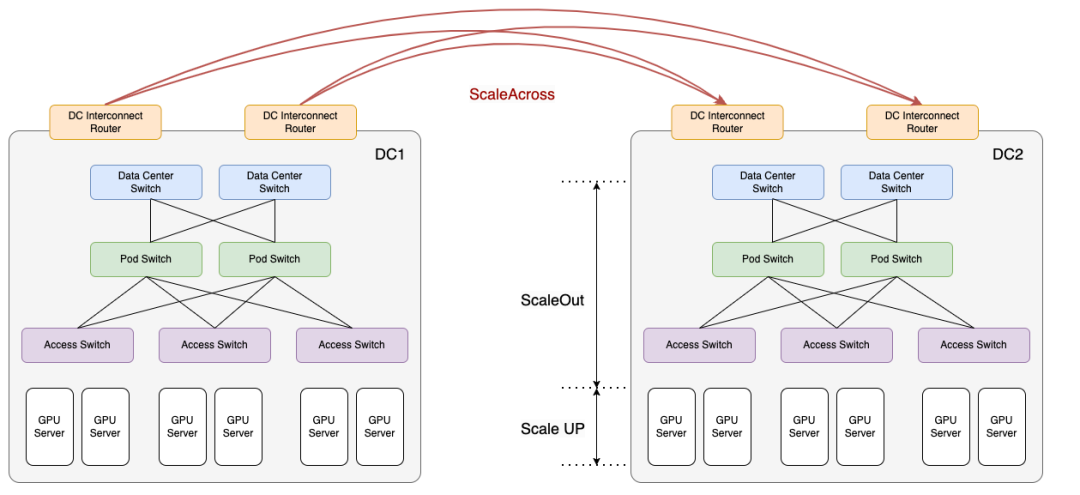
跨域扩展网络(Scale Across)是将多个数据中心互连,使其能够作为一统一集群共享工作负载。其核心在于通过高带宽,横向扩展网络搭建数据中心间的桥梁,提供远高于传统数据中心互联的传输能力。
为何需要 Scale-Across
既然 Scale-Up 与 Scale-Out 仍在持续发展,为何还需推动 Scale Across?事实上,跨域扩展并非取代既有架构,而是应对以下几方面系统级挑战的必然演进:
MetroX-2:城域级 AI 互联系统
为应对上述挑战, NVIDIA 推出了面向“城域级 AI 网络”的 InfiniBand 远程互连系统 MetroX-2。在传统网络中,跨机房、跨园区通信往往意味着更高的延迟、更复杂的路由路径,以及难以预测的抖动(Jitter),这些因素对AI训练与推理任务影响显著。
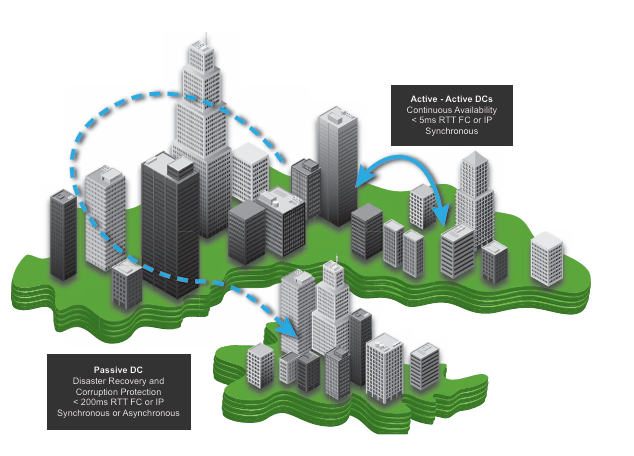
MetroX-2 通过多层次协同优化,将地理距离的影响降至可接受范围:
该系统通过面向 AI 流量优化的以太网架构、高带宽低延迟数据路径,以及与 NVIDIA 生态深度协同的流量调度机制,使 GPU 间通信具备“距离透明性”。从应用视角看,训练与推理任务仍运行在一个统一、低延迟、可预测的网络平面上。
对训练与推理工作负载的实际价值
在大模型训练阶段,涉及模型并行、流水线并行等复杂通信模式时,跨节点通信往往占据总训练时间的相当比例。MetroX-2 的低抖动、高可预测性特征,使得这些通信模式在跨数据中心场景下仍然能够保持稳定的 step time,而不会因为偶发拥塞导致整体训练节奏被拖慢。
而在推理场景中,MetroX-2 的价值体现得更加直接。
推理工作负载天然具有突发性、高并发和强时延敏感等特征。通过在城域范围内部署多个推理节点,并利用 MetroX-2 将它们组织成一个统一资源池,可以实现更精细的流量调度与就近响应:
这使AI服务商无需在每个区域部署完整冗余的推理集群,即可在保证体验的同时实现资源的高效利用。
超擎数智:构建AI工厂的可持续物理底座
如果说 AI 网络架构的前一阶段是从三层架构走向 Clos Fabric,那么下一阶段则是从“数据中心网络”迈向“AI 城域网络”。
在 MetroX-2 构筑的城域级 AI 网络中,更长的链路距离与更复杂的室外环境,对光互联产品的传输距离、损耗控制、稳定性与可靠性提出了远超传统数据中心的严苛要求。
作为 AI 原生的基础设施整体解决方案提供商,超擎数智在长距离光模块与高性能光纤线缆领域厚植优势,产品方案能完美匹配跨城域、高带宽、低误码的应用场景,提供极其稳定、可预测的 AI 基础设施服务,确保跨数据中心的 GPU 通信不因链路质量而产生瓶颈。
在 AI 基础设施从“算力堆叠”走向“系统工程”的今天,选择成熟、可靠的光互联方案,本质上是为未来的 AI 工厂铺设一条可持续扩展的高速通道。超擎数智,愿做这条通道背后坚实的支撑力量。

公众号


电话

需求反馈
