


















咨询服务热线:400-0698-860
邮箱:info@chaoqing-i.com
业务中心 - 上海超擎数智科技有限公司:上海市徐汇区龙启路158号1幢灿星大厦19层1911
业务中心 - 北京超擎数智科技有限公司:北京市海淀区北三环西路99号西海国际中心1号楼907
研发中心 - 武汉超擎数智科技有限公司:武汉东湖高新区金融港二路9号联发科武汉研发中心2楼





随着大型模型(LLM)向长上下文和多步推理演进,“上下文” 已从模型内部的短期记忆,扩展为需要跨节点、跨存储层级高效共享和访问的巨大键值(KV)缓存,KV缓存的存储效率成为核心瓶颈。NVIDIA BlueField-4(简称 BF4)及其驱动的平台,正致力于在数据平面、存储与网络层构建一个低延迟、高带宽、可扩展的“上下文记忆层”,以系统化应对这一挑战。
01 上下文:AI的认知基石
许多人将“上下文”简单等同于历史聊天记录,这其实是对AI认知的片面理解。本质上,上下文是LLM进行下一步推理或生成任务所需的全部信息集合。
引用一张图来进行概括:
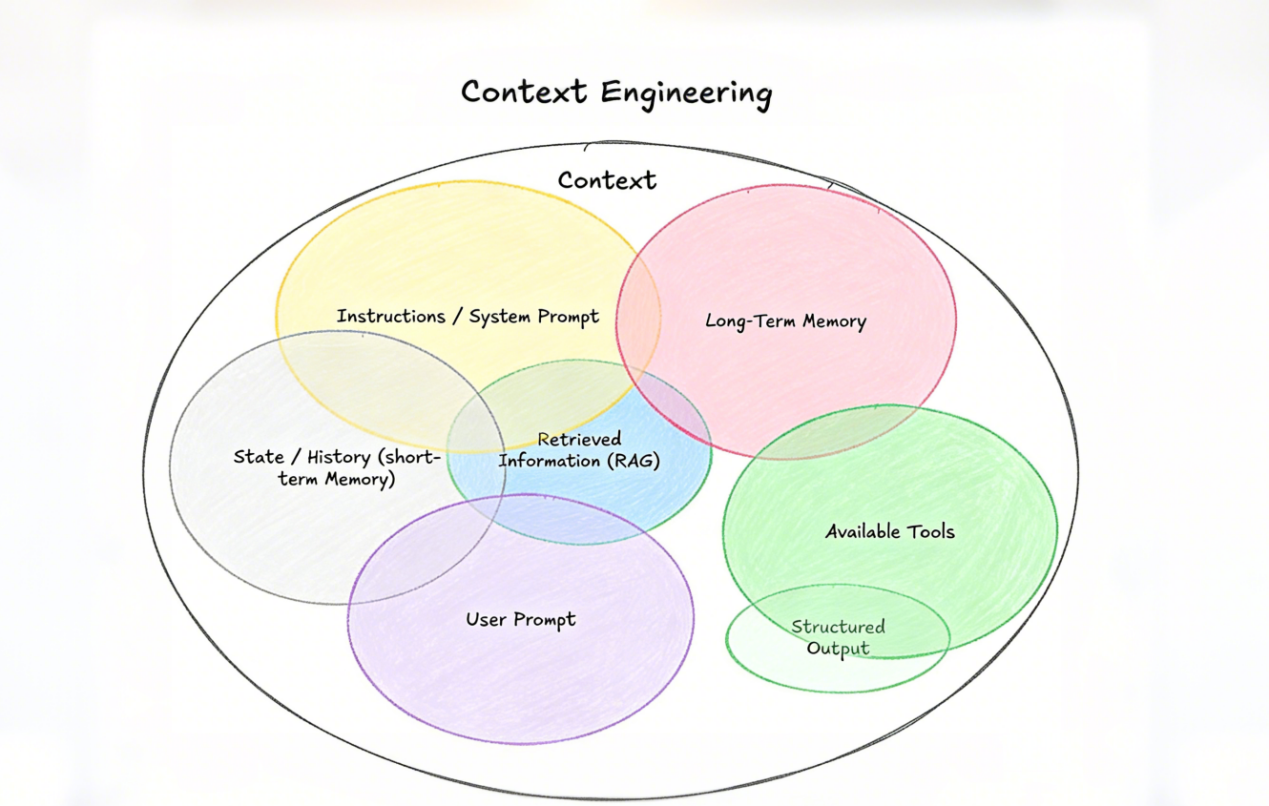
上下文工程的成败,往往决定了AI Agent的成败。
上下文如同人类理解语言时所需的背景知识与逻辑链条。充足且连贯的上下文,不仅可以帮助AI理解用户的真实意图、情绪倾向以及隐含需求,更是能在长文本写作、复杂问题求解及多智能体协作中保持逻辑一致性,避免“幻觉”的关键。简而言之,上下文让AI拥有了“记住”并基于过往信息推进任务的能力。
02 上下文存储:KV Cache的分层困境
随着上下文窗口不断扩大,KV缓存的容量需求呈线性增长趋势,而重新计算历史上下文的算力成本则呈指数级上升。因此,KV缓存的高效存储与重用已成为提升性能和降低成本的关键。
这一趋势显著加剧了现有内存层级的压力。当前,AI提供商通常在昂贵的高带宽内存(HBM)与面向持久化及通用数据管理的通用存储层之间权衡,缺乏专为临时、AI原生KV缓存的存储方案。这种结构性缺口不仅推高了功耗和单token成本,也导致昂贵的GPU资源无法被充分利用。
与此同时,模型正从简单的无状态聊天机器人,演进为支持多轮交互、具备复杂工作流的智能代理。随着模型规模迈向数万亿参数、上下文窗口扩展至数百万token,KV 缓存规模急剧膨胀,并需在更长会话中持续存在、在不同推理服务间高效共享,进一步凸显了存储与系统架构层面的挑战。
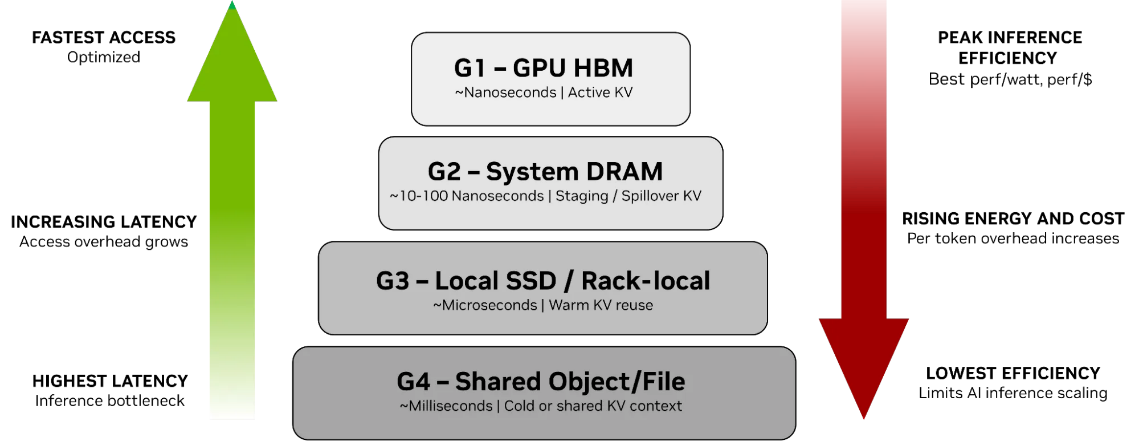
现有AI 推理中的 KV 缓存采用分层存储架构:
随着上下文规模增长,KV缓存迅速耗尽G1–G3的本地资源,被迫下沉到G4,带来显著的延迟上升、能耗增加与成本压力。总体规律是:KV离GPU越远,延迟越高,能效越低,每代币成本越大。性能优化内存与容量优化存储之间的鸿沟,已成为AI扩展的核心瓶颈。
因此,业界亟需一个专门的上下文层,将KV缓存视为AI原生数据类型进行独立管理,而不是挤占稀缺的HBM或依赖通用存储方案。
03 BlueField-4:构建推理上下文的专用记忆层
针对上文所描述的KV Cache分层困境,NVIDIA 基于BlueField-4提出的“Inference Context Memory”思路,正是在网络/存储层引入一个低延迟、可由DPU硬件加速管理的上下文层(包括高速 KV cache 与预分发机制),把“预置可复用的上下文”放在靠近GPU的可直接RDMA访问位置,显著减少主机CPU/操作系统的控制平面干预和数据拷贝开销。这个思路可以把每秒可处理的token数(TPS)和能效成比例提升。
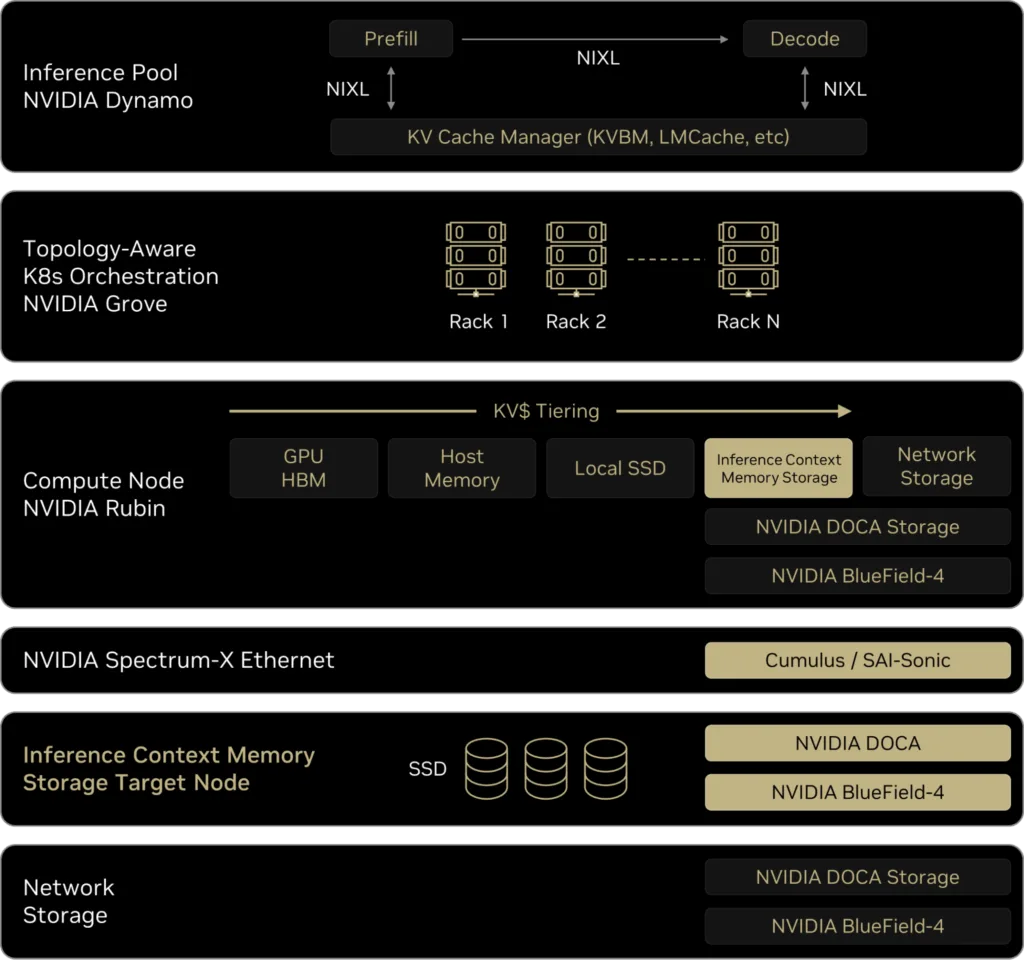
NVIDIA Inference 上下文内存存储平台是一套面向大上下文推理的集成化存储基础设施。该平台基于 NVIDIA BlueField-4 DPU,在 舱级(pod-level)构建专用上下文内存层,弥合GPU高速HBM内存与可扩展共享存储之间的性能与能效差距,显著加速KV 缓存的访问与跨节点共享。
其核心是引入一个全新的G3.5存储层——通过以太网连接、专为KV缓存优化的闪存层。该层充当AI舱的“代理长期记忆”,既具备足够容量支持多代理共享与持续演进的上下文,又足够接近计算侧,可高效将数据预取回GPU和主机内存,而不影响解码延迟。
每个GPU舱可获得PB级共享容量,使长上下文工作负载在被HBM和DRAM驱逐后仍能保留历史状态。G3.5 层以“低功耗闪存”形式扩展了GPU/主机的内存层级,提供远优于传统共享存储的聚合带宽与效率,将 KV 缓存转变为可被统一编排的高带宽共享资源,避免在每个节点重复实现缓存机制。
在这一架构下:
这种分工显著降低了G4的容量与带宽压力,同时保持了关键历史数据的可追溯性。
04 结语:从可选项变为必选项
BlueField-4的核心价值在于,它将 “上下文”从传统模糊的内存角色中剥离,构建了一个专用、可扩展、跨节点共享的上下文记忆层。对于下一代依赖长期记忆、多轮推理和多智能体协同的AI系统而言,BlueField-4正在从基础设施的“可选项”变为“必选项”。
超擎数智深度聚焦AIDC(AI 数据中心)网络基础设施,围绕大模型训练与推理场景,提供高性能、低时延、高可靠的网络产品解决方案。我们在设计中全面对齐 NVIDIA AI工厂架构,对 NVIDIA Spectrum-X、BlueField DPU、NVLink / InfiniBand / RoCE 等关键技术体系具备深入理解和实践经验,能够从网络拓扑、拥塞控制、GPU互联到AI负载特性进行系统级优化。
依托与 NVIDIA 生态的紧密协同,超擎数智的网络产品可有效支撑大规模GPU集群、长上下文推理和多租户AI业务,帮助客户最大化释放算力价值,加速AI基础设施的规模化落地与商业落地。

公众号


电话

需求反馈
