


















咨询服务热线:400-0698-860
邮箱:info@chaoqing-i.com
业务中心 - 上海超擎数智科技有限公司:上海市徐汇区龙启路158号1幢灿星大厦19层1911
业务中心 - 北京超擎数智科技有限公司:北京市海淀区北三环西路99号西海国际中心1号楼907
研发中心 - 武汉超擎数智科技有限公司:武汉东湖高新区金融港二路9号联发科武汉研发中心2楼





在 AI 算力需求爆发的当下,企业对高效、稳定的算力基座需求愈发迫切。超擎数智最新发布的元景系列 CQ7668-L AI服务器以 “双核心” 配置强势破局 —— 一边是能实现 800Gbps 高速互联的 CX-8 架构,为多 GPU 协同提供低延迟、高带宽的通信保障;另一边是深度适配的 RTX PRO Server 系列 GPU,凭借第五代 Tensor 核心与高功率设计,直接拉满 AI 训练与推理性能。当 CX-8 的互联优势遇上 RTX PRO Server 的算力实力,两者双强合璧不仅打破传统服务器的算力瓶颈,更能为企业级 AI 场景(如大模型训练、工业仿真、智能数据分析)提供 “即部署、即高效” 的算力支持,真正引爆 AI 时代的算力潜能。

产品优势
多元算力,构建面向未来的智能计算中枢
CQ7668-L RTX PRO Server AI服务器作为面向未来的智能算力中枢,通过多元算力引擎全面兼容多种品牌AI加速卡,多种异构计算架构满足训练/推理/HPC等差异化需求。支持CX-8 SuperNIC架构,集成800Gb/s高速网络,集群Scale-out总带宽提升300%,单GPU带宽达400Gb/s,为智能计算提供全方位算力支撑。
卓越硬件配置,突破AI计算极限
CQ7668-L RTX PRO Server搭载2颗英特尔®至强®第六代(Granite Rapids)可扩展处理器,单颗处理器最高支持86核,配合32条6400MT/s DDR5内存通道,可扩展至8TB超大内存容量,显著提升高并发计算任务的吞吐效率。在存储方面,该服务器采用16个2.5英寸热插拔盘位设计,支持SATA/SAS/NVMe混合部署模式,单机最高可配置200TB全闪存存储,充分满足AI训练、大数据分析等高吞吐场景的存储需求。
此外,该机型提供1个OCP 3.0专用网卡插槽及多个PCIe扩展槽,支持高速网络适配器(如200/400Gb)及GPU加速卡,确保计算、存储、网络三大关键性能的协同优化,为AI训练、推理、高性能计算等应用提供灵活且高效的智算方案。
应用场景
大模型推理
在处理高并发、低延迟的AI推理任务时(如大型语言模型API服务、实时视频分析),CX-8的超高网络带宽确保了数据能快速涌入,而GPU的强大算力则能快速处理并返回结果。GPUDirect RDMA 技术可以让接收到的网络数据直接进入GPU显存,跳过CPU拷贝,显著降低推理延迟。
下一代全息渲染与数字孪生
这超越了传统的3D渲染,追求物理世界的极致数字化。
内存级延迟的分布式计算
CX-8的InfiniBand支持使得多台服务器之间的GPU通信延迟接近本地NVLink。
高性能计算与科学模拟
高端虚拟化与云工作站
使用 NVIDIA vGPU技术,可以将强大的RTX PRO 6000D(双芯)灵活地切分给多个虚拟机使用。CX-8的架构确保了在多个vGPU实例之间能有高效的资源调度和数据隔离。同时,其高速网络能力使得远程用户(如设计师、工程师)能够获得与本地工作站无异的极致图形体验。
自动驾驶仿真与合成数据生成
为了训练和验证自动驾驶AI,需要创建数百万个不同的驾驶场景。一台这样的服务器可以同时运行数十个高保真的虚拟世界。RTX 6000D负责渲染每个世界的传感器数据(摄像头、激光雷达),而CX-8的PCIe Switch确保了每个虚拟世界的海量场景数据能从存储快速加载到GPU,并将仿真结果快速输出到中心数据库,极大地加速了自动驾驶模型的迭代。
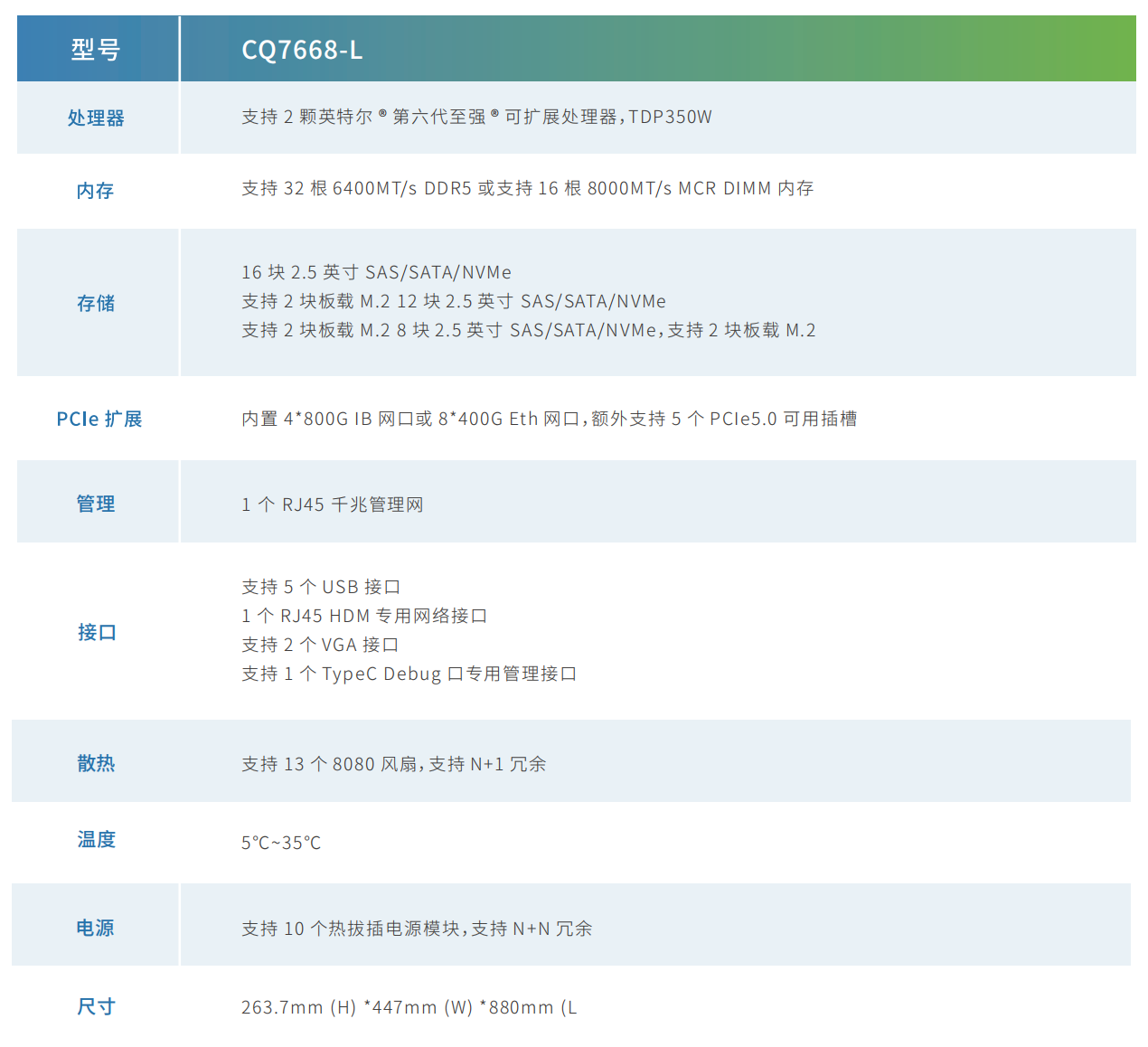
产品规格
超擎优势
多种机头测试环境
超擎数智已率先完成RTX PRO Server AI服务器部署与网络深度优化,包含直通、Switch、CX-8三种机头测试环境,提前验证方案稳定性与适配性。当多数企业还在纠结硬件选择、环境调试时,超擎已为你备好成熟可靠的 “即用型” 基础,让 RTX PRO Server落地快人一步。
全周期专业支持
基于海量测试积累的场景经验,超擎数智会先帮您做需求分析,提供贴合业务的部署建议;后续使用中,无论遇到性能适配问题,还是技术故障,超擎数智团队都能快速响应,用实战经验帮你排忧解难。在为用户“搭好环境”的同时,更让RTX PRO Server 的算力精准匹配业务需求,最大化发挥其性能价值。
元景系列 CQ7668-L AI服务器的发布,不仅标志着超擎数智在推理应用多元算力架构上的重要突破,更为用户构建下一代AI基础设施提供了坚实底座。未来,超擎将持续深耕AI应用全栈方案,携手用户与合作伙伴,推动AI算力普惠化、场景化与规模化发展,赋能千行百业智能化转型。

公众号


电话

需求反馈
