


















咨询服务热线:400-0698-860
邮箱:info@chaoqing-i.com
业务中心 - 上海超擎数智科技有限公司:上海市徐汇区龙启路158号1幢灿星大厦19层1911
业务中心 - 北京超擎数智科技有限公司:北京市海淀区北三环西路99号西海国际中心1号楼907
研发中心 - 武汉超擎数智科技有限公司:武汉东湖高新区金融港二路9号联发科武汉研发中心2楼





在AI和高性能计算领域,存储系统的带宽和并行处理能力已成为影响整体计算性能的关键瓶颈。随着NVIDIA推出新一代Blackwell和Rubin GPU,其强大的计算能力需要匹配更高速、更高并行的存储架构。本文将深入分析智算中心为何应采用基于InfiniBand网络的并行存储解决方案,以充分发挥最新GPU的性能优势,并满足多客户、高并发的数据处理需求。
深度学习的训练过程是一个高度迭代的过程。同一份数据往往需要被re-read,这意味着:
总结来看,GPU 负责计算,而存储和缓存系统负责“供能”。只有当数据供应充足且高效时,GPU 的超强算力才能真正释放出来,在理想情况下,数据会在你第一次读取的时候就被缓存下来,这样后面就不用每次都跑到网络上去取了。一般来说,共享文件系统会先用内存(RAM)做第一层缓存——从缓存里读数据的速度,比直接从远程存储拉取要快一个量级。除此之外,GPU服务器还自带本地NVMe 存储,可以用来做数据缓存,或者作为数据分阶段加载的中转站,让整体的数据处理更高效。
存储的性能在一定程度上取决于网络的可用性与稳定,传统以太网在低延迟、拥塞控制和大规模并发场景中往往捉襟见肘,InfiniBand网络则凭借其一系列特性,成为AIDC存储网络的最佳搭档:
极致带宽与高并发处理能力
带宽翻倍:单计算节点带宽从200Gb/s提升到400Gb/s,在多客户并发访问的场景下,200/400G InfiniBand网络能够确保GPU服务器都能获得充足的存储带宽资源,避免性能瓶颈。
高并发支持:200G InfiniBand网络支持更多的并发连接,能够同时处理数千个客户端的I/O请求,显著提升并行存储系统的吞吐量。例如,在大规模AI训练场景中,多个GPU节点可以同时从存储系统中读取数据,而不会出现带宽争用或延迟增加的问题。
超低延迟与高效数据访问
极致的端到端延迟:200G InfiniBand网络的超低延迟特性,使得并行存储系统能够快速响应客户端的请求,减少数据访问的等待时间。这对于实时性要求高的应用(如推荐系统、自动驾驶)至关重要。
RDMA零拷贝技术:通过绕过CPU直接访问存储数据,减少了数据搬移的开销,进一步提升了并行存储系统的效率。在多客户并发访问的场景下,RDMA技术能够显著降低CPU负载,确保系统的高性能运行。
AI优化与动态负载均衡
In-Network Computing:并行存储支持多样化的缓存技术,减少数据搬移,提升并行存储系统的效率。例如,在AI训练场景中,数据预处理可以直接在存储系统中完成,减少GPU的等待时间。
动态连接管理:存储网络使用200G InfiniBand网络,保证高性能的同时,还能够根据负载情况动态调整连接,确保并行存储系统在高并发场景下的稳定性和性能。例如,在科学模拟场景中,多个研究团队可以同时访问存储系统,而不会出现性能下降的问题。
大规模扩展性
InfiniBand的分层拓扑和网络管理机制,使其能在数千甚至上万节点的AI集群中保持性能稳定。
实际部署案例
1、方案设备选型
网卡使用:
MCX653106A-HDAT/MCX755106AS-HEAT
交换机:
MQM9790-NS2F/MQM9700-NS2F
连接件:
Leaf-server:MFA7U10-H010
Leaf-spine:MMA4Z00-NS,MFP7E10-N020
2、网络top设计
Leaf-sever使用MFA7U10-H010 400G to 2X200G AOC,200G端连接两台不同服务器;leaf-spine使用800G多模模块MMA4Z00-NS;可根据存储节点与计算节点数量设置合适的收敛比。
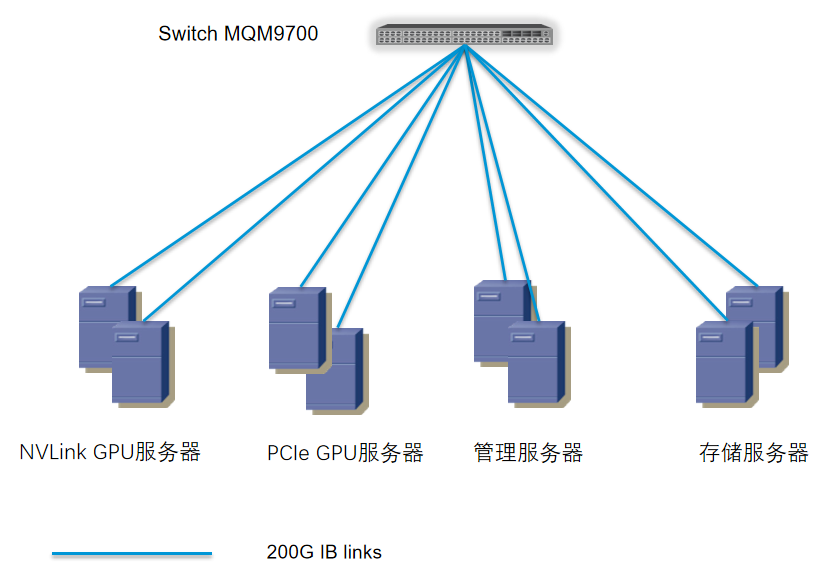
3、方案优势
作为NVIDIA Compute(GPU)、Networking(网络)的双Elite精英级合作伙伴,超擎数智凭借对AIDC场景下高速率网络的理解,和丰富的高性能网络项目实施经验,可为智算中心提供完整的基于InfiniBand网络的并行存储解决方案,利用InfiniBand网络的高带宽、低延迟、RDMA等特性,轻松解决AI算力的存储瓶颈,打造支撑万卡集群的AIDC网络架构。

公众号


电话

需求反馈
